Einen Flow ausführen und auswerten#
Nachdem Sie den Flow in einem Flow initialisieren und testen entwickelt und getestet haben, hilft Ihnen diese Anleitung, einen Flow mit einem größeren Datensatz auszuführen und den erstellten Flow auszuwerten.
Einen Batch-Lauf erstellen#
Da Sie Ihren Flow erfolgreich mit einem kleinen Datensatz ausgeführt haben, möchten Sie vielleicht testen, ob er auch bei großen Datensätzen gut funktioniert. Sie können einen Batch-Test durchführen und die Ergebnisse überprüfen.
Ein Massentest ermöglicht es Ihnen, Ihren Flow mit einem großen Datensatz auszuführen und Ausgaben für jede Datenzeile zu generieren. Die Laufergebnisse werden in einer lokalen Datenbank aufgezeichnet, sodass Sie jederzeit pf-Befehle verwenden können, um die Laufergebnisse anzuzeigen (z. B. pf run list).
Lassen Sie uns einen Lauf mit dem Flow web-classification erstellen. Dies ist ein Flow, der die Mehrklassenklassifizierung mit LLMs demonstriert. Gegeben eine URL, klassifiziert er die URL mit wenigen Schüssen, einfacher Zusammenfassung und Klassifizierungs-Prompts in eine Webkategorie.
Um mit der Anleitung zu beginnen, benötigen Sie
Klonen Sie das Beispiel-Repository (Link zum Flow oben) und setzen Sie das Arbeitsverzeichnis auf
<Pfad-zum-Beispiel-Repo>/examples/flows/.Stellen Sie sicher, dass Sie die notwendige Verbindung bereits erstellt haben.
Erstellen Sie den Lauf mit Flow und Daten. Sie können --stream hinzufügen, um den Lauf zu streamen.
pf run create --flow standard/web-classification --data standard/web-classification/data.jsonl --column-mapping url='${data.url}' --stream
Hinweis: column-mapping ist eine Zuordnung von Flow-Eingabenamen zu angegebenen Werten. Weitere Details finden Sie unter Spaltenzuordnung verwenden.
Sie können den Lauf auch benennen, indem Sie --name my_first_run im obigen Befehl angeben. Andernfalls wird der Laufname nach einem bestimmten Muster mit Zeitstempel generiert.
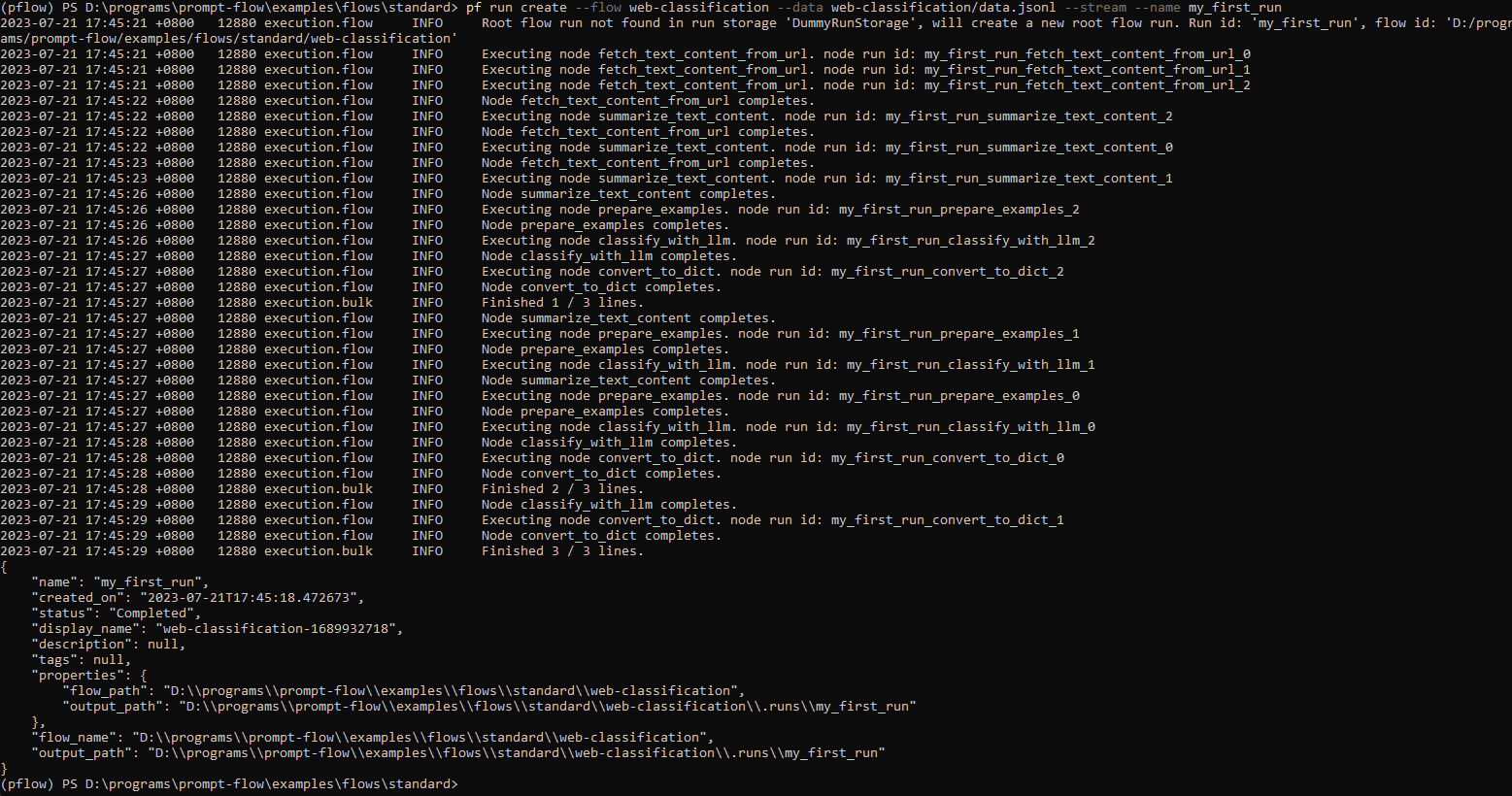
Mit einem Laufnamen können Sie die Laufergebnisse einfach über die folgenden Befehle anzeigen oder visualisieren
pf run show-details -n my_first_run

pf run visualize -n my_first_run
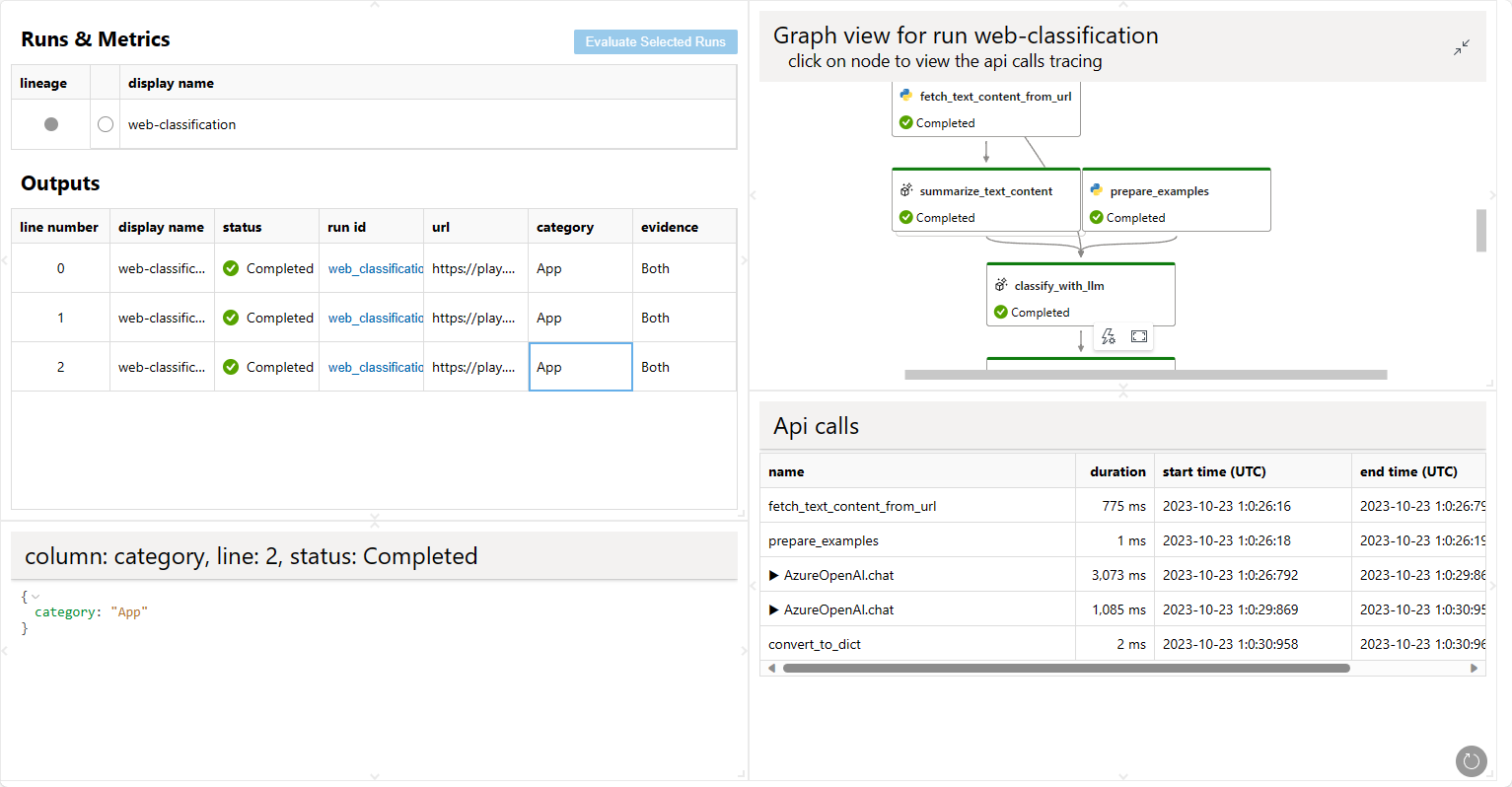
Weitere Details finden Sie unter pf run --help.
from promptflow.client import PFClient
# Please protect the entry point by using `if __name__ == '__main__':`,
# otherwise it would cause unintended side effect when promptflow spawn worker processes.
# Ref: https://docs.pythonlang.de/3/library/multiprocessing.html#the-spawn-and-forkserver-start-methods
if __name__ == "__main__":
# PFClient can help manage your runs and connections.
pf = PFClient()
# Set flow path and run input data
flow = "standard/web-classification" # set the flow directory
data= "standard/web-classification/data.jsonl" # set the data file
# create a run, stream it until it's finished
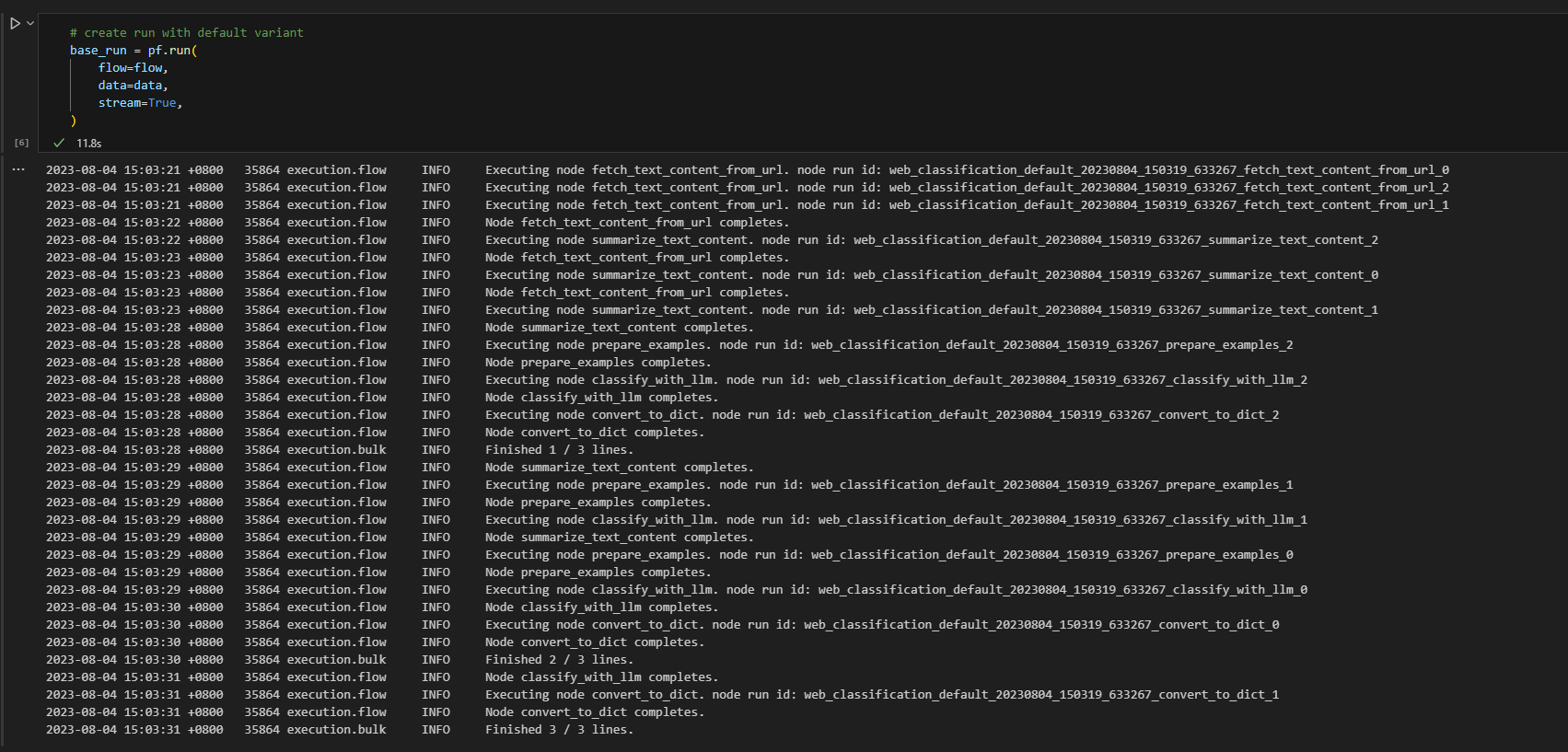
base_run = pf.run(
flow=flow,
data=data,
stream=True,
# map the url field from the data to the url input of the flow
column_mapping={"url": "${data.url}"},
)
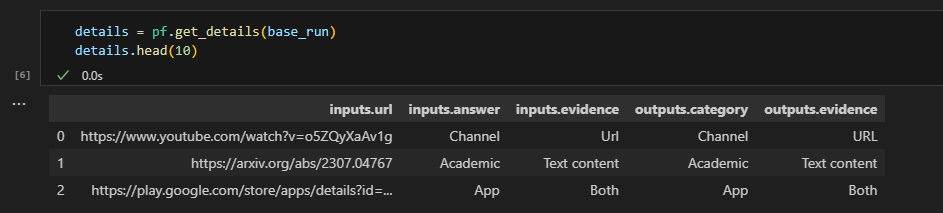
# get the inputs/outputs details of a finished run.
details = pf.get_details(base_run)
details.head(10)
# visualize the run in a web browser
pf.visualize(base_run)
Sie können sich gerne die Promptflow Python Library Reference für alle öffentlichen Schnittstellen der SDK ansehen.
Verwenden Sie die Code-Lens-Aktion oben im YAML-Editor, um einen Batch-Lauf auszulösen 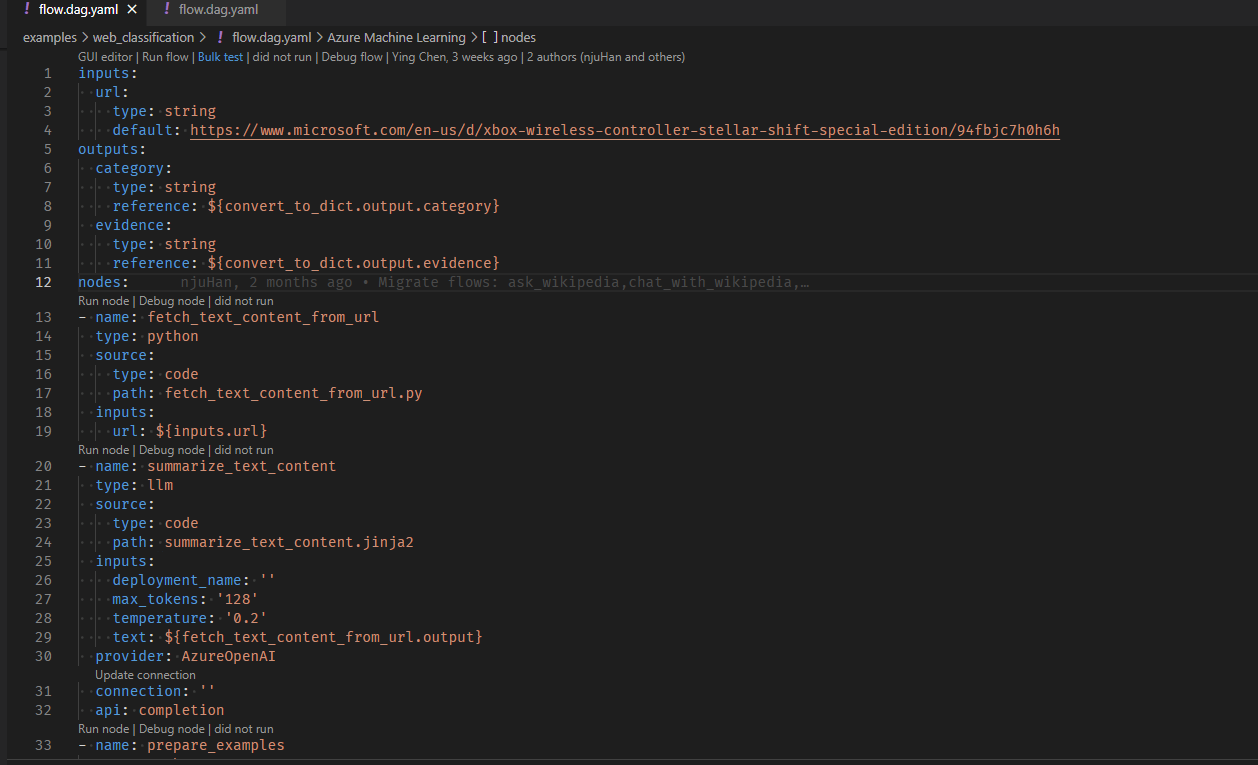
Klicken Sie auf die Schaltfläche für den Massentest oben im visuellen Editor, um den Flow-Test auszulösen. 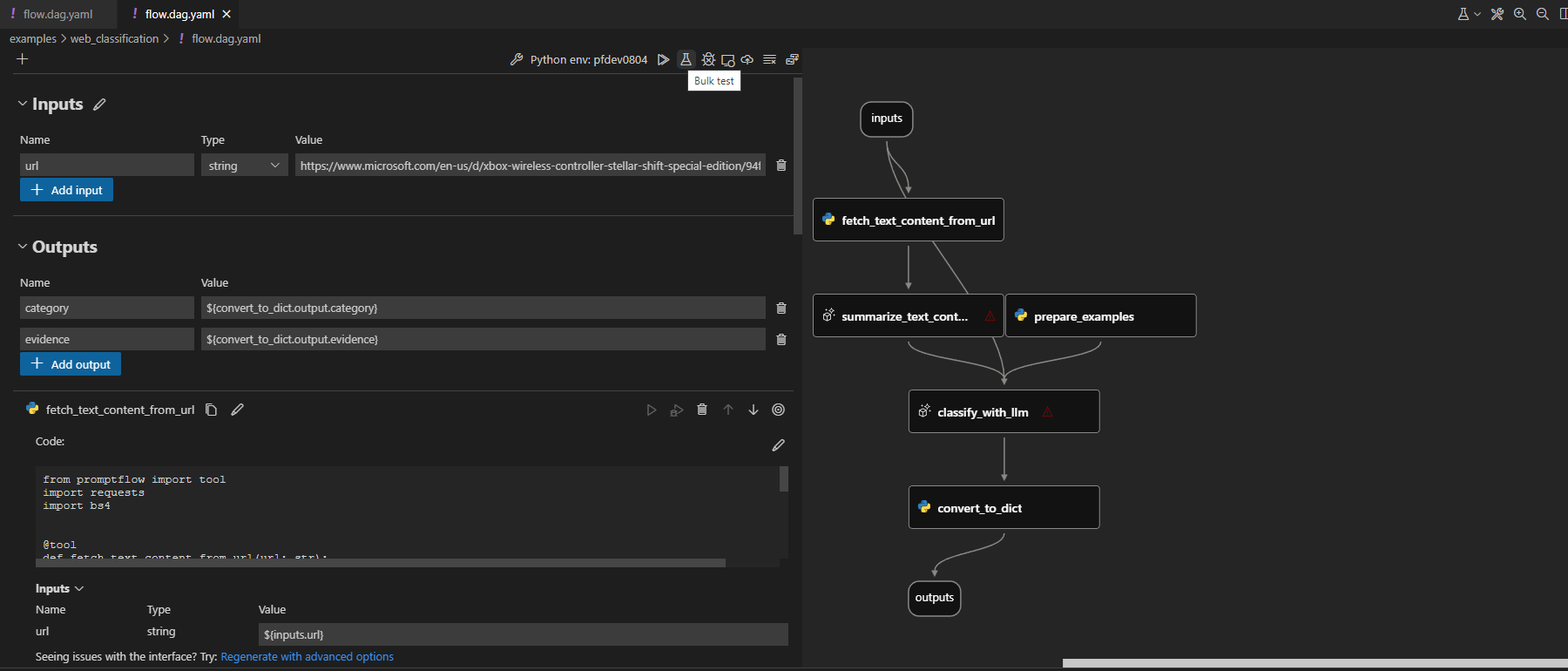
Wir haben auch eine detailliertere Dokumentation Läufe verwalten, die zeigt, wie Sie Ihre abgeschlossenen Läufe mit CLI, SDK und VS Code Extension verwalten.
Bewerten Sie Ihren Flow#
Sie können eine Bewertungsmethode verwenden, um Ihren Flow zu bewerten. Die Bewertungsmethoden sind ebenfalls Flows, die Python oder LLM usw. verwenden, um Metriken wie Genauigkeit und Relevanz zu berechnen. Weitere Informationen zur Entwicklung eines Bewertungs-Flows finden Sie unter Evaluierungs-Flow entwickeln.
In dieser Anleitung verwenden wir den Flow eval-classification-accuracy zur Bewertung. Dies ist ein Flow, der die Leistung eines Klassifizierungssystems bewertet. Er vergleicht jede Vorhersage mit der Groundtruth und vergibt eine Note Correct oder Incorrect und aggregiert die Ergebnisse, um Metriken wie accuracy zu erzeugen, die widerspiegelt, wie gut das System die Daten klassifiziert.
Bewertungs-Flow gegen Lauf ausführen#
Den abgeschlossenen Flow-Lauf bewerten
Nachdem der Lauf abgeschlossen ist, können Sie den Lauf mit dem folgenden Befehl bewerten. Verglichen mit dem normalen Befehl zum Erstellen eines Laufs gibt es zwei zusätzliche Argumente
column-mapping: Eine Zuordnung von Flow-Eingabenamen zu angegebenen Datenwerten. Referenzieren Sie hier für detaillierte Informationen.run: Der Name des Flows, der bewertet werden soll.
Weitere Details finden Sie unter Spaltenzuordnung verwenden.
pf run create --flow evaluation/eval-classification-accuracy --data standard/web-classification/data.jsonl --column-mapping groundtruth='${data.answer}' prediction='${run.outputs.category}' --run my_first_run --stream
Wie beim vorherigen Lauf können Sie den Bewertungs-Laufnamen mit --name my_first_eval_run im obigen Befehl angeben.
Sie können die Laufergebnisse auch streamen oder anzeigen mit
pf run stream -n my_first_eval_run # same as "--stream" in command "run create"
pf run show-details -n my_first_eval_run
pf run show-metrics -n my_first_eval_run
Da Sie nun zwei verschiedene Läufe haben, my_first_run und my_first_eval_run, können Sie die beiden Läufe gleichzeitig mit dem folgenden Befehl visualisieren.
pf run visualize -n "my_first_run,my_first_eval_run"
Ein Webbrowser wird geöffnet, um das Visualisierungsergebnis anzuzeigen.
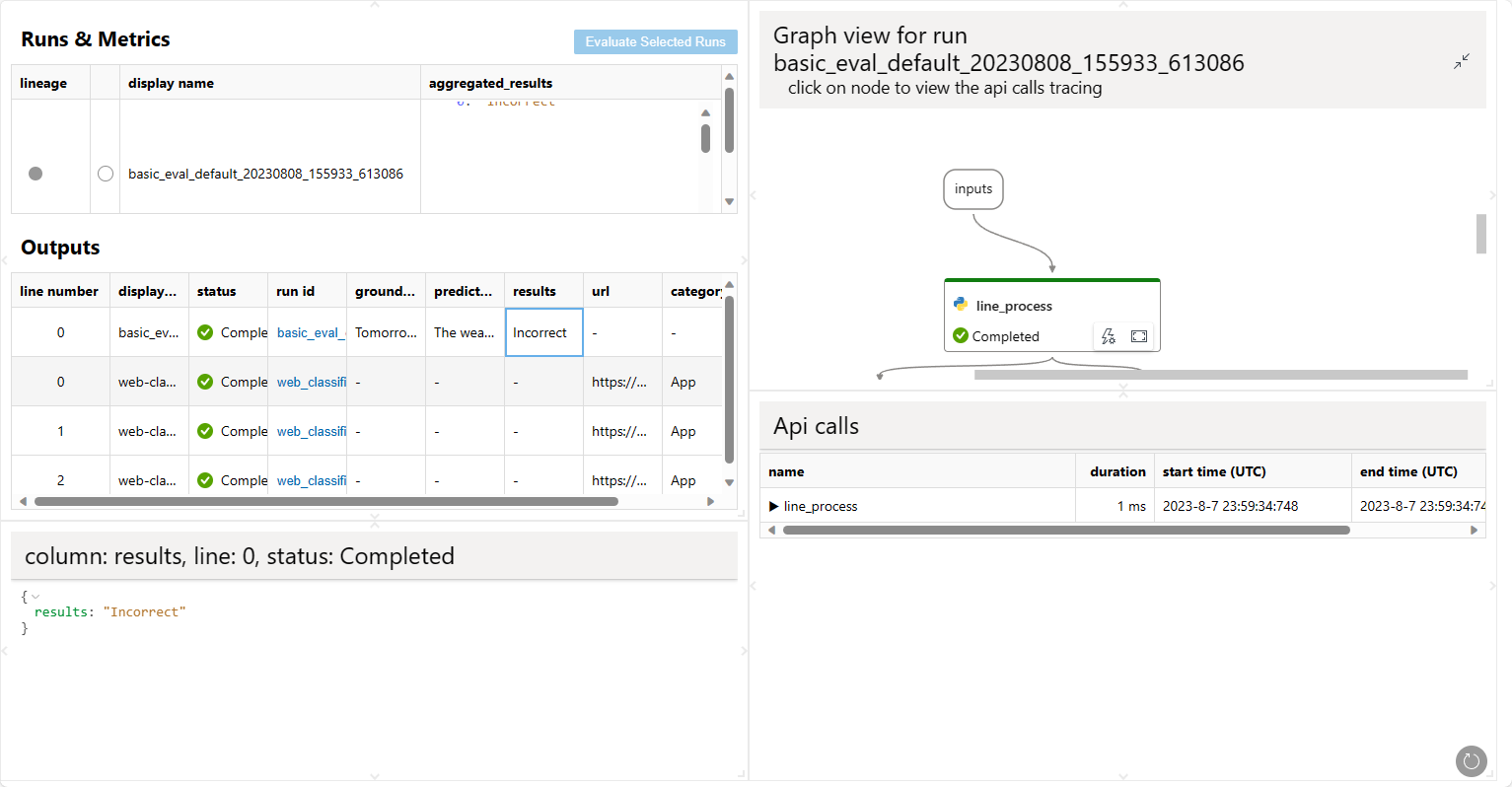
Den abgeschlossenen Flow-Lauf bewerten
Nachdem der Lauf abgeschlossen ist, können Sie den Lauf mit dem folgenden Befehl bewerten. Verglichen mit dem normalen Befehl zum Erstellen eines Laufs gibt es zwei zusätzliche Argumente
column-mapping: Ein Wörterbuch, das die Quellen der Eingabedaten repräsentiert, die für die Bewertungsmethode benötigt werden. Die Quellen können aus der Flow-Lauf-Ausgabe oder aus Ihrem Testdatensatz stammen.Wenn die Datenspalte in Ihrem Testdatensatz enthalten ist, wird sie als
${data.<Spaltenname>}angegeben.Wenn die Datenspalte aus Ihrer Flow-Ausgabe stammt, wird sie als
${run.outputs.<Ausgabenname>}angegeben.
run: Der Name oder die Laufinstanz des zu bewertenden Flow-Laufs.
Weitere Details finden Sie unter Spaltenzuordnung verwenden.
from promptflow.client import PFClient
# PFClient can help manage your runs and connections.
pf = PFClient()
# set eval flow path
eval_flow = "evaluation/eval-classification-accuracy"
data= "standard/web-classification/data.jsonl"
# run the flow with existing run
eval_run = pf.run(
flow=eval_flow,
data=data,
run=base_run,
column_mapping={ # map the url field from the data to the url input of the flow
"groundtruth": "${data.answer}",
"prediction": "${run.outputs.category}",
}
)
# stream the run until it's finished
pf.stream(eval_run)
# get the inputs/outputs details of a finished run.
details = pf.get_details(eval_run)
details.head(10)
# view the metrics of the eval run
metrics = pf.get_metrics(eval_run)
print(json.dumps(metrics, indent=4))
# visualize both the base run and the eval run
pf.visualize([base_run, eval_run])
Ein Webbrowser wird geöffnet, um das Visualisierungsergebnis anzuzeigen.
Es gibt Aktionen zum Auslösen lokaler Batch-Läufe. Um eine Bewertung durchzuführen, können Sie die Aktionen zur Auswertung von "bestehenden Läufen" verwenden.
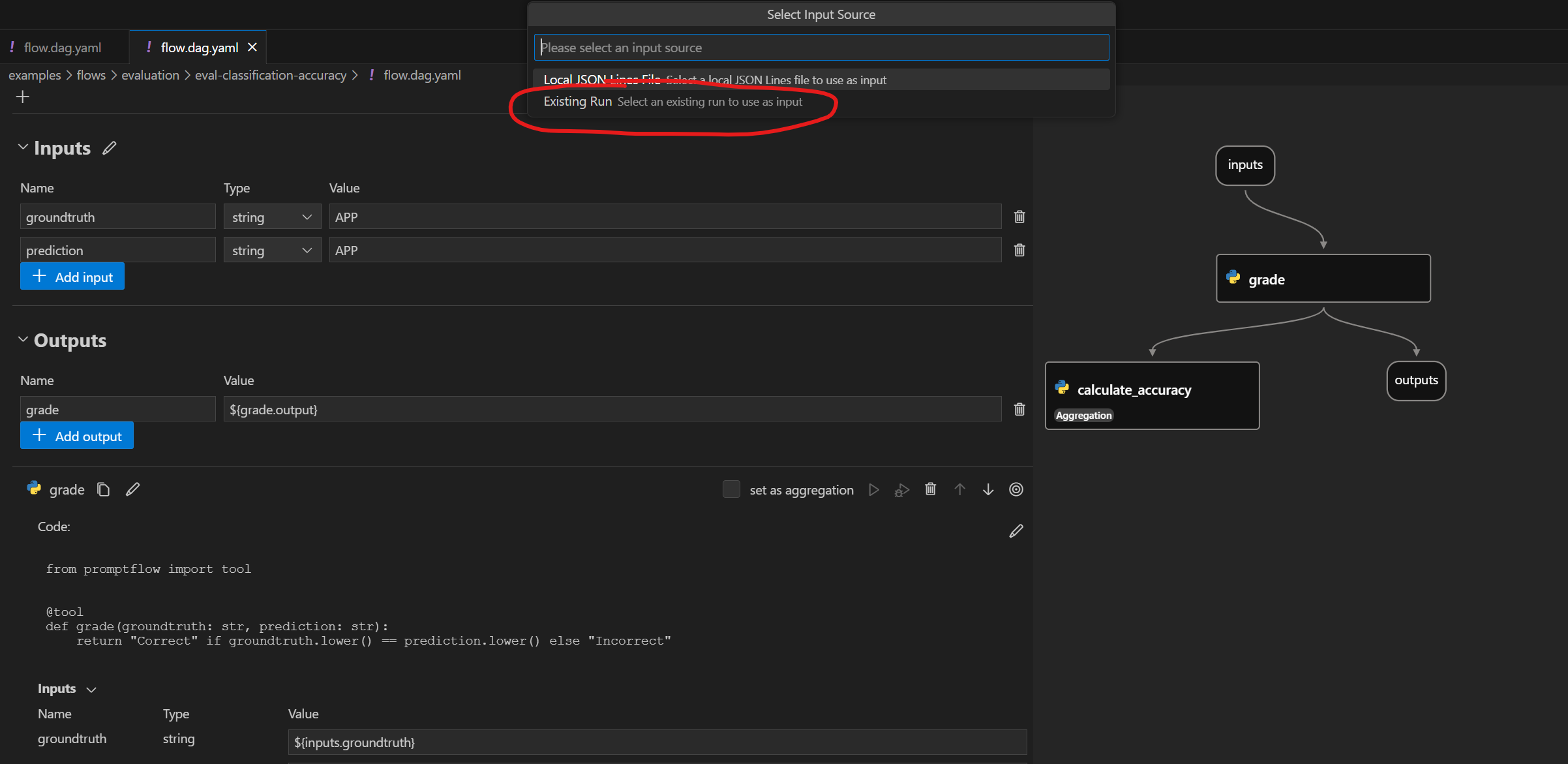
Nächste Schritte#
Erfahren Sie mehr über