Ausführen von Flows in Azure ML-Pipelines#
Autor(en): 

Warum Azure Machine Learning (ML) Pipelines verwenden, um Ihre Flows in der Cloud auszuführen?#
In realen Szenarien dienen Flows verschiedenen Zwecken. Betrachten Sie beispielsweise einen Flow, der dazu dient, die Relevanzbewertung für eine Kommunikationssitzung zwischen Menschen und Agenten zu ermitteln. Angenommen, Sie möchten diesen Flow jeden Abend auslösen, um die Leistung des Tages zu bewerten und Spitzenzeiten für LLM (Language Model)-Endpunkte zu vermeiden. In diesem gängigen Szenario treten häufig folgende Anforderungen auf:
Verarbeitung großer Dateneingaben: Ausführen von Flows mit Tausenden oder Millionen von Dateneingaben auf einmal.
Skalierbarkeit und Effizienz: Anforderungen an eine skalierbare, effiziente und ausfallsichere Plattform, um den Erfolg sicherzustellen.
Automatisierung: Automatisches Auslösen von Batch-Flows, wenn vorgelagerte Daten bereit sind oder zu festgelegten Intervallen.
Azure ML Pipelines erfüllen all diese Offline-Anforderungen effektiv. Durch die Integration von Prompt Flows und Azure ML Pipelines können Flow-Benutzer die oben genannten Ziele sehr einfach erreichen, und in diesem Tutorial lernen Sie:
Wie Sie das Python SDK verwenden, um Ihren Flow automatisch in einen „Schritt“ in einer Azure ML-Pipeline zu konvertieren.
Wie Sie Ihre Daten in die Pipeline einspeisen, um die Batch-Flow-Ausführungen auszulösen.
Wie Sie andere Pipeline-Schritte vor oder nach Ihrem Prompt Flow-Schritt erstellen. z. B. Datenvorverarbeitung oder Ergebnisaggregation.
Wie Sie einen einfachen Zeitplan für Ihre Pipeline einrichten.
Wie Sie die Pipeline für einen Azure ML Batch-Endpunkt bereitstellen. Dann können Sie sie bei Bedarf mit neuen Daten aufrufen.
Bevor Sie beginnen, beachten Sie die folgenden Voraussetzungen:
Einführung in die Azure ML-Plattform
Verstehen Sie, was Azure ML Pipelines und Komponenten sind.
Azure Cloud-Einrichtung
Ein Azure-Konto mit einem aktiven Abonnement - Konto kostenlos erstellen
Erstellen Sie eine Azure ML-Ressource über das Azure-Portal – Azure ML-Arbeitsbereich erstellen
Stellen Sie eine Verbindung zu Ihrem Arbeitsbereich her und richten Sie dann einen grundlegenden Computercluster ein – Arbeitsbereich konfigurieren
Lokale Umgebungs-Einrichtung
Eine Python-Umgebung
Installiertes Azure Machine Learning Python SDK v2 – Installationsanweisungen – Überprüfen Sie den Abschnitt „Erste Schritte“ und stellen Sie sicher, dass die Version von „azure-ai-ml“ höher ist als
1.12.0.
1. Verbindung zum Azure Machine Learning-Arbeitsbereich herstellen#
Der Arbeitsbereich ist die übergeordnete Ressource für Azure Machine Learning und bietet einen zentralen Ort, um mit allen Artefakten zu arbeiten, die Sie bei der Verwendung von Azure Machine Learning erstellen. In diesem Abschnitt stellen wir eine Verbindung zu dem Arbeitsbereich her, in dem der Auftrag ausgeführt wird.
1.1 Die erforderlichen Bibliotheken importieren#
# import required libraries
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
from azure.ai.ml import MLClient, load_component, Input, Output
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
1.2 Anmeldeinformationen konfigurieren#
Wir verwenden DefaultAzureCredential, um Zugriff auf den Arbeitsbereich zu erhalten. DefaultAzureCredential sollte in der Lage sein, die meisten Szenarien zur Authentifizierung mit dem Azure SDK zu bewältigen.
Referenz für weitere verfügbare Anmeldeinformationen, falls dies nicht für Sie funktioniert: Beispiel für die Anmeldeinformationskonfiguration, Referenzdokumentation zu azure-identity.
try:
credential = DefaultAzureCredential()
# Check if given credential can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential not work
credential = InteractiveBrowserCredential()
1.3 Ein Handle für den Arbeitsbereich erhalten#
Wir verwenden eine „Konfigurationsdatei“, um eine Verbindung zu Ihrem Arbeitsbereich herzustellen. Überprüfen Sie dieses Notebook, um Ihre Konfigurationsdatei aus dem Azure ML-Arbeitsbereichsportal zu erhalten und sie in diesen Ordner einzufügen. Wenn Sie dann den nächsten Codeblock ausführen, ist die Umgebung eingerichtet.
# Get a handle to workspace
ml_client = MLClient.from_config(credential=credential)
# Retrieve an already attached Azure Machine Learning Compute.
cluster_name = "cpu-cluster"
print(ml_client.compute.get(cluster_name))
2. Flow als Komponente laden#
Wenn Sie bereits einen Flow mit dem Promptflow SDK oder Portal erstellt haben, finden Sie die Datei flow.dag.yaml im Flow-Ordner. Diese YAML-Spezifikation ist unerlässlich, um Ihren Flow in eine Azure ML-Komponente zu laden.
HINWEIS: Um die Funktion
load_componentmit flow.dag.yaml zu verwenden, stellen Sie bitte Folgendes sicher:
Der
$schemamuss in der Ziel-DAG-YAML-Datei definiert sein. Beispiel:$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Flow.schema.json.Flow-Metadaten müssen generiert und auf dem neuesten Stand gehalten werden, indem die Datei „
/.promptflow/flow.tools.json“ überprüft wird. Wenn sie nicht vorhanden ist, führen Sie den folgenden Befehl aus, um sie zu generieren und zu aktualisieren: pf flow validate --source <mein-Flow-Verzeichnis>.
flow_component = load_component("../../flows/standard/web-classification/flow.dag.yaml")
Bei Verwendung der Funktion load_component und der Flow-YAML-Spezifikation wird Ihr Flow automatisch in eine Parallelkomponente umgewandelt. Diese Parallelkomponente ist für die groß angelegte, Offline- und parallele Verarbeitung mit Effizienz und Ausfallsicherheit konzipiert. Hier sind einige Hauptmerkmale dieser automatisch konvertierten Komponente:
Vordefinierte Ein- und Ausgabeports
Portname |
type |
description |
|---|---|---|
data |
uri_folder oder uri_file |
Akzeptiert Batch-Dateneingaben für Ihren Flow. Sie können entweder den Datentyp |
flow_outputs |
uri_file |
Erzeugt eine einzelne Ausgabedatei namens parallel_run_step.jsonl. Jede Zeile in dieser Datendatei entspricht einem JSON-Objekt, das die Flow-Rückgaben darstellt, zusammen mit einer zusätzlichen Spalte namens line_number, die seine Position in der ursprünglichen Datei angibt. |
debug_info |
uri_folder |
Wenn Sie Ihre Flow-Komponente im Debug-Modus ausführen, stellt dieser Port Debugging-Informationen für jede Ausführung Ihrer Zeilen bereit. z. B. Zwischenausgaben zwischen Schritten oder LLM-Antworten und Token-Nutzung. |
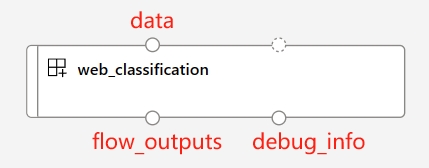
HINWEIS
flow_outputsunddebug_infoAusgaben müssen als Ausgabe-Modusmountgesetzt werden, wenn Sie pf-Komponenten mit mehreren Knoten ausführen.
Automatisch generierte Parameter
Diese Parameter repräsentieren alle Ihre Flow-Eingaben und Verbindungen, die mit Ihren Flow-Schritten verbunden sind. Sie können Standardwerte in der Flow-/Run-Definition festlegen und diese während der Job-Einreichung weiter anpassen. Verwenden Sie beispielsweise den Beispiel-Flow „web-classification“. Dieser Flow hat nur eine Eingabe namens „url“ und 2 LLM-Schritte „summarize_text_content“ und „classify_with_llm“. Die Eingabeparameter dieser Flow-Komponente sind:
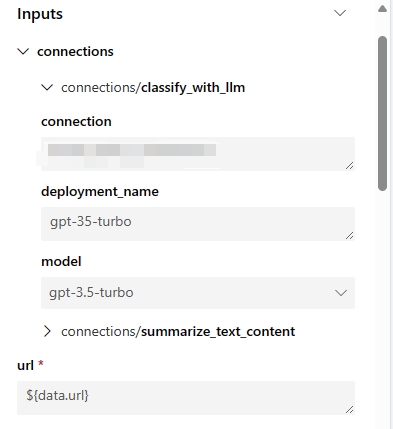
Automatisch generierte Umgebung
Die Umgebung der erstellten Komponente wird vom neuesten Promptflow Runtime-Image übernommen. Benutzer können benutzerdefinierte Pakete in der Umgebung einschließen, indem sie das Attribut
environmentinflow.dag.yamlfestlegen, zusammen mit einer ‚requirements.txt‘-Datei, die sich im selben Flow-Ordner befindet.... environment: python_requirements_txt: requirements.txt
3. Pipeline erstellen#
3.1 Eingabe und Ausgabe deklarieren#
Um Ihre Pipeline mit Daten zu versorgen, müssen Sie eine Eingabe mit den Eigenschaften path, type und mode deklarieren. Bitte beachten Sie: mount ist der Standard- und empfohlene Modus für Ihre Datei- oder Ordnerdateneingabe.
Die Deklaration der Pipeline-Ausgabe ist optional. Wenn Sie jedoch einen benutzerdefinierten Ausgabepfad in der Cloud benötigen, können Sie dem folgenden Beispiel folgen, um den Pfad im Datenspeicher festzulegen. Weitere detaillierte Informationen zu gültigen Pfadwerten finden Sie in dieser Dokumentation – Pipeline-Ein- und Ausgaben verwalten.
data_input = Input(
path="../../flows/standard/web-classification/data.jsonl",
type=AssetTypes.URI_FILE,
mode="mount",
)
pipeline_output = Output(
# Provide custom flow output file path if needed
# path="azureml://datastores/<data_store_name>/paths/<path>",
type=AssetTypes.URI_FOLDER,
# rw_mount is suggested for flow output
mode="rw_mount",
)
3.2.1 Pipeline mit einzelner Flow-Komponente ausführen#
Da alle Promptflow-Komponenten auf Azure ML Parallelkomponenten basieren, können Benutzer spezielle Ausführungseinstellungen nutzen, um die Parallelisierung von Flow-Ausführungen zu steuern. Nachfolgend sind einige nützliche Einstellungen aufgeführt:
Ausführungseinstellungen |
description |
Zulässige Werte |
Standardwert |
|---|---|---|---|
PF_INPUT_FORMAT |
Wenn |
json, jsonl, csv, tsv |
jsonl |
compute |
Legt fest, welcher Computercluster aus Ihrem Azure ML-Arbeitsbereich für diesen Job verwendet wird. |
||
instance_count |
Legt fest, wie viele Knoten Ihres Computerclusters diesem Job zugewiesen werden. |
von 1 bis zur Anzahl der Knoten des Computerclusters. |
1 |
max_concurrency_per_instance |
Legt fest, wie viele dedizierte Prozessoren den Flow parallel auf 1 Knoten ausführen. In Kombination mit der Einstellung „instance_count“ beträgt die Gesamtdurchsatzrate Ihres Flows instance_count*max_concurrency_per_instance. |
>1 |
1 |
mini_batch_size |
Legt die Anzahl der Zeilen pro Mini-Batch fest. Ein Mini-Batch ist die grundlegende Granularität für die Verarbeitung vollständiger Daten mit Parallelisierung. Jeder Worker-Prozessor verarbeitet einen Mini-Batch auf einmal, und alle Worker arbeiten parallel über verschiedene Knoten hinweg. |
> 0 |
1 |
max_retries |
Legt die Anzahl der Wiederholungsversuche fest, wenn ein Mini-Batch eine interne Ausnahme auslöst. |
>= 0 |
3 |
error_threshold |
Legt fest, wie viele fehlgeschlagene Zeilen akzeptabel sind. Wenn die Anzahl der fehlgeschlagenen Zeilen diesen Schwellenwert überschreitet, wird der Job gestoppt und als fehlgeschlagen markiert. Setzen Sie „-1“, um diese Fehlerprüfung zu deaktivieren. |
-1 oder >=0 |
-1 |
mini_batch_error_threshold |
Legt die maximale Anzahl fehlgeschlagener Mini-Batches fest, die nach allen Wiederholungsversuchen toleriert werden können. Setzen Sie „-1“, um diese Fehlerprüfung zu deaktivieren. |
-1 oder >=0 |
-1 |
logging_level |
Bestimmt, wie Paralleljobs Protokolle auf der Festplatte speichern. Das Einstellen auf „DEBUG“ für die Flow-Komponente ermöglicht es der Komponente, Zwischen-Flow-Protokolle an den Port „debug_info“ auszugeben. |
INFO, WARNING, DEBUG |
INFO |
timeout |
Legt die Timeout-Überprüfung für die Ausführung jedes Mini-Batches in Millisekunden fest. Wenn ein Mini-Batch länger als dieser Schwellenwert läuft, wird er als fehlgeschlagen markiert und der nächste Wiederholungsversuch ausgelöst. Berücksichtigen Sie einen höheren Wert basierend auf Ihrer Mini-Batch-Größe und dem gesamten Datenverkehr für Ihre LLM-Endpunkte. |
> 0 |
600 |
# Define the pipeline as a function
@pipeline()
def pipeline_func_with_flow(
# Function inputs will be treated as pipeline input data or parameters.
# Pipeline input could be linked to step inputs to pass data between steps.
# Users are not required to define pipeline inputs.
# With pipeline inputs, user can provide the different data or values when they trigger different pipeline runs.
pipeline_input_data: Input,
parallel_node_count: int = 1,
):
# Declare pipeline step 'flow_node' by using flow component
flow_node = flow_component(
# Bind the pipeline intput data to the port 'data' of the flow component
# If you don't have pipeline input, you can directly pass the 'data_input' object to the 'data'
# But with this approach, you can't provide different data when you trigger different pipeline runs.
# data=data_input,
data=pipeline_input_data,
# Declare which column of input data should be mapped to flow input
# the value pattern follows ${data.<column_name_from_data_input>}
url="${data.url}",
# Provide the connection values of the flow component
# The value of connection and deployment_name should align with your workspace connection settings.
connections={
"summarize_text_content": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
"classify_with_llm": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
},
)
# Provide run settings of your flow component
# Only 'compute' is required and other setting will keep default value if not provided.
flow_node.environment_variables = {
"PF_INPUT_FORMAT": "jsonl",
}
flow_node.compute = "cpu-cluster"
flow_node.resources = {"instance_count": parallel_node_count}
flow_node.mini_batch_size = 5
flow_node.max_concurrency_per_instance = 2
flow_node.retry_settings = {
"max_retries": 1,
"timeout": 1200,
}
flow_node.error_threshold = -1
flow_node.mini_batch_error_threshold = -1
flow_node.logging_level = "DEBUG"
# Function return will be treated as pipeline output. This is not required.
return {"flow_result_folder": flow_node.outputs.flow_outputs}
# create pipeline instance
pipeline_job_def = pipeline_func_with_flow(pipeline_input_data=data_input)
pipeline_job_def.outputs.flow_result_folder = pipeline_output
Reichen Sie den Pipeline-Job in Ihrem Arbeitsbereich ein und überprüfen Sie dann den Status Ihres Jobs in der Benutzeroberfläche über den Link in der Ausgabe.
# Submit the pipeline job to your workspace
pipeline_job_run = ml_client.jobs.create_or_update(
pipeline_job_def, experiment_name="Single_flow_component_pipeline_job"
)
pipeline_job_run
ml_client.jobs.stream(pipeline_job_run.name)
HINWEIS
Die Wahl von
mini_batch_sizehat erheblichen Einfluss auf die Effizienz des Flow-Jobs. Da die Zeilen innerhalb jedes Mini-Batches sequenziell ausgeführt werden, erhöht ein höherer Wert für diesen Parameter die Blockgröße, was die Parallelisierung verringert. Andererseits erhöhen größere Batch-Größen auch die Kosten für Wiederholungsversuche, da Wiederholungsversuche auf dem gesamten Mini-Batch basieren. Umgekehrt kann die Wahl des niedrigsten Werts (z. B. mini_batch_size=1) zu zusätzlichem Overhead führen, was die Effizienz über mehrere Mini-Batches hinweg bei der Orchestrierung oder Ergebniszusammenfassung beeinträchtigt. Daher wird empfohlen, mit einem Wert zwischen 10 und 100 zu beginnen und ihn später basierend auf Ihren spezifischen Anforderungen zu optimieren.Die Einstellung
max_concurrency_per_instancekann die parallele Effizienz innerhalb eines einzelnen Compute-Knotens erheblich verbessern. Sie birgt jedoch auch mehrere potenzielle Probleme: 1) Erhöhung des Risikos, dass der Speicher ausgeht, 2) LLM-Endpunkte können eine Drosselung erfahren, wenn zu viele Anfragen gleichzeitig eintreffen. Im Allgemeinen ist es ratsam, die Anzahl von max_concurrency_per_instance gleich der Kernanzahl Ihres Compute festzulegen, um ein Gleichgewicht zwischen Parallelität und Ressourceneinschränkungen zu finden.
3.2.2 Komplexen Pipeline mit mehreren Komponenten ausführen#
In einer typischen Pipeline finden Sie mehrere Schritte, die alle Ihre Offline-Geschäftsanforderungen abdecken. Wenn Sie eine komplexere Pipeline für die Produktion erstellen möchten, erkunden Sie die folgenden Ressourcen:
Verschiedene Komponententypen
Darüber hinaus finden Sie hier ein Beispiel-Code, das zwei zusätzliche Befehlskomponenten aus einem Repository lädt, um eine einzelne Offline-Pipeline zu erstellen:
data_prep_component: Dieser Dummy-Schritt zur Datenvorverarbeitung führt eine einfache Datensampelsierung durch.
result_parser_component: Kombiniert Quelldaten, Flow-Ergebnisse und Debugging-Ausgaben, um eine einzelne Datei zu generieren, die ursprüngliche Abfragen, LLM-Vorhersagen und LLM-Token-Nutzungen enthält.
# load Azure ML components
data_prep_component = load_component("./components/data-prep/data-prep.yaml")
result_parser_component = load_component(
"./components/result-parser/result-parser.yaml"
)
# load flow as component
flow_component = load_component("../../flows/standard/web-classification/flow.dag.yaml")
@pipeline()
def pipeline_func_with_flow(pipeline_input_data):
data_prep_node = data_prep_component(
input_data_file=pipeline_input_data,
)
data_prep_node.compute = "cpu-cluster"
flow_node = flow_component(
# Feed the output of data_prep_node to the flow component
data=data_prep_node.outputs.output_data_folder,
url="${data.url}",
connections={
"summarize_text_content": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
"classify_with_llm": {
"connection": "azure_open_ai_connection",
"deployment_name": "gpt-35-turbo",
},
},
)
flow_node.environment_variables = {"PF_INPUT_FORMAT": "csv"}
flow_node.compute = "cpu-cluster"
flow_node.mini_batch_size = 5
flow_node.max_concurrency_per_instance = 2
flow_node.resources = {"instance_count": 1}
flow_node.logging_level = "DEBUG"
# set output mode to 'mount'
# This is required for the flow component when the 'instance_count' is set higher than 1
flow_node.outputs.flow_outputs.mode = "mount"
flow_node.outputs.debug_info.mode = "mount"
result_parser_node = result_parser_component(
source_data=data_prep_node.outputs.output_data_folder,
pf_output_data=flow_node.outputs.flow_outputs,
pf_debug_data=flow_node.outputs.debug_info,
)
flow_node.retry_settings = {
"max_retries": 1,
"timeout": 6000,
}
result_parser_node.compute = "cpu-cluster"
return {"flow_result_folder": result_parser_node.outputs.merged_data}
# create pipeline instance
pipeline_job_def = pipeline_func_with_flow(pipeline_input_data=data_input)
pipeline_job_def.outputs.flow_result_folder = pipeline_output
Reichen Sie den Pipeline-Job in Ihrem Arbeitsbereich ein und überprüfen Sie dann den Status Ihres Jobs in der Benutzeroberfläche über den Link in der Ausgabe.
# submit job to workspace
pipeline_job_run = ml_client.jobs.create_or_update(
pipeline_job_def, experiment_name="Complex_flow_component_pipeline_job"
)
pipeline_job_run
ml_client.jobs.stream(pipeline_job_run.name)
4 Nächste Schritte#
4.1 Nächster Schritt – Zeitplan für Ihre Pipeline einrichten#
Azure Machine Learning Pipelines unterstützt native Zeitpläne, um Benutzern zu helfen, ihre Pipeline-Jobs regelmäßig mit vordefinierten Zeit-Triggern auszuführen. Hier ist ein Codebeispiel für die Einrichtung eines Zeitplans für eine neu erstellte Pipeline, die die Flow-Komponente verwendet.
Beginnen wir mit der Deklaration eines Zeitplans mit einem benutzerdefinierten Wiederholungsmuster.
from datetime import datetime
from azure.ai.ml.entities import JobSchedule, RecurrenceTrigger, RecurrencePattern
from azure.ai.ml.constants import TimeZone
schedule_name = "simple_sdk_create_schedule_recurrence"
schedule_start_time = datetime.utcnow()
recurrence_trigger = RecurrenceTrigger(
frequency="day", # could accept "hour", "minute", "day", "week", "month"
interval=1,
schedule=RecurrencePattern(hours=10, minutes=[0, 1]),
start_time=schedule_start_time,
time_zone=TimeZone.UTC,
)
job_schedule = JobSchedule(
name=schedule_name,
trigger=recurrence_trigger,
# Declare the pipeline job to be scheduled. Here we uses the pipeline job created in previous example.
create_job=pipeline_job_def,
)
Um den Zeitplan zu starten, folgen Sie diesem Beispiel:
job_schedule = ml_client.schedules.begin_create_or_update(
schedule=job_schedule
).result()
print(job_schedule)
Um alle Ihre geplanten Jobs anzuzeigen, navigieren Sie zur Seite Jobübersicht in der Benutzeroberfläche des Azure Machine Learning-Arbeitsbereichs. Jeder von einem Zeitplan ausgelöste Job hat einen Anzeigenamen im folgenden Format: <schedule_name>-<trigger_time>. Wenn Sie beispielsweise einen Zeitplan namens „named-schedule“ haben, hat ein Job, der am 1. Januar 2021 um 06:00:00 UTC ausgelöst wird, den Anzeigenamen „named-schedule-20210101T060000Z“.
Um einen laufenden Zeitplan zu deaktivieren oder zu beenden, folgen Sie diesem Beispiel:
job_schedule = ml_client.schedules.begin_disable(name=schedule_name).result()
job_schedule.is_enabled
Weitere Details zur Planung von Azure Machine Learning-Pipeline-Jobs finden Sie in diesem Artikel über die Planung von Pipeline-Jobs.
4.2 Nächster Schritt – Pipeline für einen Endpunkt bereitstellen#
Azure Machine Learning bietet auch Batch-Endpunkte, die es Ihnen ermöglichen, Pipelines für eine effiziente Operationalisierung bereitzustellen. Wenn Sie Zeitpläne für Ihre Flow-Pipeline mithilfe eines externen Orchestrators wie Azure Data Factory oder Microsoft Fabric benötigen, ist die Verwendung von Batch-Endpunkten die beste Empfehlung für Ihre Flow-Pipeline.
Beginnen wir mit der Erstellung eines neuen Batch-Endpunkts in Ihrem Arbeitsbereich.
from azure.ai.ml.entities import BatchEndpoint, PipelineComponentBatchDeployment
# from azure.ai.ml.entities import ModelBatchDeployment, ModelBatchDeploymentSettings, Model, AmlCompute, Data, BatchRetrySettings, CodeConfiguration, Environment, Data
# from azure.ai.ml.constants import BatchDeploymentOutputAction
endpoint_name = "hello-my-pipeline-endpoint"
endpoint = BatchEndpoint(
name=endpoint_name,
description="A hello world endpoint for pipeline",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint).result()
Jeder Endpunkt kann mehrere Bereitstellungen unterstützen, die jeweils mit unterschiedlichen Pipelines verknüpft sind. In diesem Zusammenhang initiieren wir eine neue Bereitstellung mit unserem Flow-Pipeline-Job, der auf den neu erstellten Endpunkt abzielt.
deployment = PipelineComponentBatchDeployment(
name="my-pipeline-deployment",
description="A hello world deployment with a pipeline job.",
endpoint_name=endpoint.name,
# Make sure 'pipeline_job_run' run successfully before deploying the endpoint
job_definition=pipeline_job_run,
settings={"default_compute": "cpu-cluster", "continue_on_step_failure": False},
)
ml_client.batch_deployments.begin_create_or_update(deployment).result()
# Refresh the default deployment to the latest one at our endpoint.
endpoint = ml_client.batch_endpoints.get(endpoint.name)
endpoint.defaults.deployment_name = deployment.name
ml_client.batch_endpoints.begin_create_or_update(endpoint).result()
Rufen Sie die Standardbereitstellung für den Zielendpunkt mit den entsprechenden Daten auf.
batch_endpoint_job = ml_client.batch_endpoints.invoke(
endpoint_name=endpoint.name,
inputs={"pipeline_input_data": data_input},
)
Überprüfen Sie abschließend den Aufruf in der Benutzeroberfläche des Arbeitsbereichs über den folgenden Link:
ml_client.jobs.get(batch_endpoint_job.name)
Weitere Details zu Azure Machine Learning Batch-Endpunkten finden Sie in diesem Artikel unter how-to-use-batch-pipeline-deployments.