Chat mit PDF – Testen, Evaluieren und Experimentieren#
Authored by: 

Wir führen Sie durch die Verwendung des Prompt Flow Python SDK zum Testen, Evaluieren und Experimentieren mit dem „Chat mit PDF“-Flow.
0. Abhängigkeiten installieren#
%pip install -r requirements.txt
1. Verbindungen erstellen#
Verbindungen in Prompt Flow dienen zur Verwaltung der Einstellungen für das Verhalten Ihrer Anwendung, einschließlich der Art und Weise, wie mit verschiedenen Diensten (z. B. Azure OpenAI) kommuniziert wird.
import promptflow
pf = promptflow.PFClient()
# List all the available connections
for c in pf.connections.list():
print(c.name + " (" + c.type + ")")
Sie benötigen eine Verbindung namens „open_ai_connection“, um den Chat_with_pdf-Flow auszuführen.
# create needed connection
from promptflow.entities import AzureOpenAIConnection, OpenAIConnection
try:
conn_name = "open_ai_connection"
conn = pf.connections.get(name=conn_name)
print("using existing connection")
except:
# Follow https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/create-resource?pivots=web-portal to create an Azure OpenAI resource.
connection = AzureOpenAIConnection(
name=conn_name,
api_key="<user-input>",
api_base="<test_base>",
api_type="azure",
api_version="<test_version>",
)
# use this if you have an existing OpenAI account
# connection = OpenAIConnection(
# name=conn_name,
# api_key="<user-input>",
# )
conn = pf.connections.create_or_update(connection)
print("successfully created connection")
print(conn)
2. Den Flow testen#
Hinweis: Dieses Beispiel verwendet vorab heruntergeladene PDFs und vorkompilierte FAISS-Indizes, um die Ausführungszeit zu verkürzen. Sie können die Ordner entfernen, um einen neuen Lauf zu starten.
# ./chat_with_pdf/.pdfs/ stores predownloaded PDFs
# ./chat_with_pdf/.index/ stores prebuilt index files
output = pf.flows.test(
".",
inputs={
"chat_history": [],
"pdf_url": "https://arxiv.org/pdf/1810.04805.pdf",
"question": "what is BERT?",
},
)
print(output)
3. Den Flow mit einer Datendatei ausführen#
flow_path = "."
data_path = "./data/bert-paper-qna-3-line.jsonl"
config_2k_context = {
"EMBEDDING_MODEL_DEPLOYMENT_NAME": "text-embedding-ada-002",
"CHAT_MODEL_DEPLOYMENT_NAME": "gpt-4", # change this to the name of your deployment if you're using Azure OpenAI
"PROMPT_TOKEN_LIMIT": 2000,
"MAX_COMPLETION_TOKENS": 256,
"VERBOSE": True,
"CHUNK_SIZE": 1024,
"CHUNK_OVERLAP": 64,
}
column_mapping = {
"question": "${data.question}",
"pdf_url": "${data.pdf_url}",
"chat_history": "${data.chat_history}",
"config": config_2k_context,
}
run_2k_context = pf.run(flow=flow_path, data=data_path, column_mapping=column_mapping)
pf.stream(run_2k_context)
print(run_2k_context)
pf.get_details(run_2k_context)
4. Die „Begründetheit“ evaluieren#
Der Eval-Groundedness-Flow verwendet das ChatGPT/GPT4-Modell, um die vom Chat-mit-PDF-Flow generierten Antworten zu bewerten.
eval_groundedness_flow_path = "../../evaluation/eval-groundedness/"
eval_groundedness_2k_context = pf.run(
flow=eval_groundedness_flow_path,
run=run_2k_context,
column_mapping={
"question": "${run.inputs.question}",
"answer": "${run.outputs.answer}",
"context": "${run.outputs.context}",
},
display_name="eval_groundedness_2k_context",
)
pf.stream(eval_groundedness_2k_context)
print(eval_groundedness_2k_context)
pf.get_details(eval_groundedness_2k_context)
pf.get_metrics(eval_groundedness_2k_context)
pf.visualize(eval_groundedness_2k_context)
Sie sehen dann eine Webseite wie diese. Sie liefert Ihnen Details darüber, wie jede Zeile bewertet wurde und sogar die Details zur Ausführung der Evaluierung: 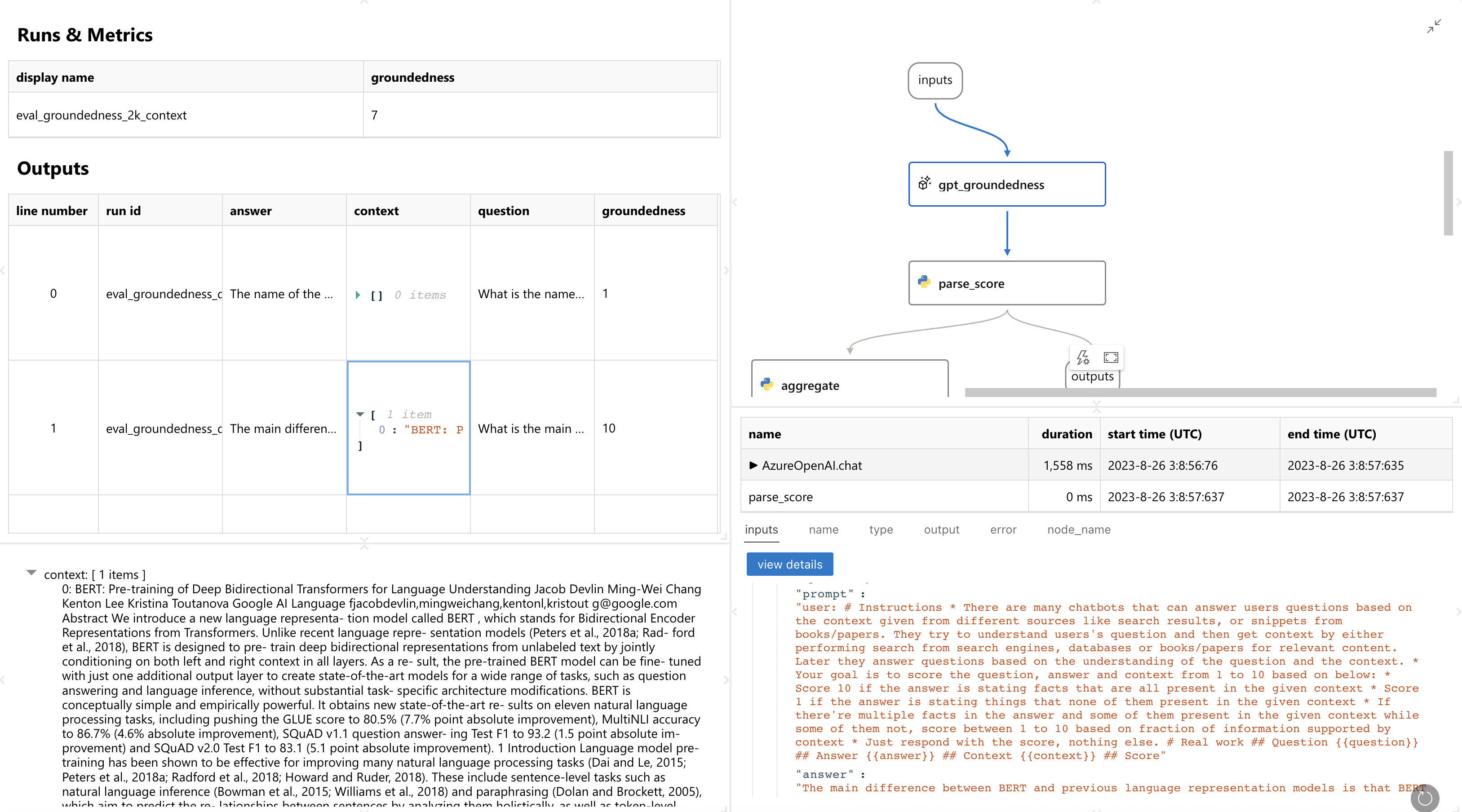
5. Eine andere Konfiguration ausprobieren und erneut evaluieren – Experimentieren#
HINWEIS: Da wir in diesem Beispiel nur 3 Zeilen Testdaten verwenden und aufgrund der nicht-deterministischen Natur von LLMs, wundern Sie sich nicht, wenn Sie bei der Ausführung dieses Prozesses exakt die gleichen Metriken sehen.
config_3k_context = {
"EMBEDDING_MODEL_DEPLOYMENT_NAME": "text-embedding-ada-002",
"CHAT_MODEL_DEPLOYMENT_NAME": "gpt-4", # change this to the name of your deployment if you're using Azure OpenAI
"PROMPT_TOKEN_LIMIT": 3000,
"MAX_COMPLETION_TOKENS": 256,
"VERBOSE": True,
"CHUNK_SIZE": 1024,
"CHUNK_OVERLAP": 64,
}
run_3k_context = pf.run(flow=flow_path, data=data_path, column_mapping=column_mapping)
pf.stream(run_3k_context)
print(run_3k_context)
eval_groundedness_3k_context = pf.run(
flow=eval_groundedness_flow_path,
run=run_3k_context,
column_mapping={
"question": "${run.inputs.question}",
"answer": "${run.outputs.answer}",
"context": "${run.outputs.context}",
},
display_name="eval_groundedness_3k_context",
)
pf.stream(eval_groundedness_3k_context)
print(eval_groundedness_3k_context)
pf.get_details(eval_groundedness_3k_context)
pf.visualize([eval_groundedness_2k_context, eval_groundedness_3k_context])