Bewertung der Leistungsvorteile von Garnet
Wir haben Garnet gründlich in verschiedenen Bereitstellungsmodi getestet
- Gleiche lokale Maschine für Client und Server
- Zwei lokale Maschinen - ein Client und ein Server
- Azure Windows VMs
- Azure Linux VMs
Unten konzentrieren wir uns auf eine ausgewählte Auswahl von Schlüsselergebnissen.
Einrichtung
Wir stellen zwei Azure Standard F72s v2 virtuelle Maschinen (jeweils 72 vCPUs, 144 GiB Speicher) unter Linux (Ubuntu 20.04) mit beschleunigtem TCP bereit. Der Vorteil dieser SKU ist, dass wir garantiert nicht mit einer anderen VM ko-lokalisiert sind, was die Leistung optimiert. Eine Maschine führt verschiedene Cache-Store-Server aus, die andere ist dem Ausgeben von Workloads gewidmet. Wir verwenden unser Benchmark-Tool namens Resp.benchmark, um alle Ergebnisse zu generieren. Wir vergleichen Garnet mit den neuesten Open-Source-Versionen von Redis (v7.2), KeyDB (v6.3.4) und Dragonfly (v6.2.11) zum Zeitpunkt der Erstellung dieses Dokuments. Wir verwenden eine gleichmäßige Zufallsverteilung von Schlüsseln in diesen Experimenten (das Shared-Memory-Design von Garnet profitiert noch mehr von verzerrten Workloads). Alle Daten passen in diesen Experimenten in den Speicher. Die Basissysteme wurden basierend auf verfügbaren Informationen so gut wie möglich abgestimmt und optimiert. Unten fassen wir für jedes System die Startkonfiguration zusammen, die für unsere Experimente verwendet wurde.
Garnet
dotnet run -c Release --framework=net8.0 --project Garnet/main/GarnetServer -- \
--bind $host \
--port $port \
--no-pubsub \
--no-obj \
--index 1g
Redis 7.2
./redis-server \
--bind $host \
--port $port \
--logfile "" \
--save "" \
--appendonly no \
--protected-mode no \
--io-threads 32
KeyDB 6.3.4
./keydb-server \
--bind $host \
--port $port \
--logfile "" \
--protected-mode no \
--save "" \
--appendonly no \
--server-threads 16 \
--server-thread-affinity true
Dragonfly 6.2.11
./dragonfly \
--alsologtostderr \
--bind $host \
--port $port \
--df_snapshot_format false \
--dbfilename "" \
--max_client_iobuf_len 10485760
Leistung grundlegender Befehle
Wir haben den Durchsatz und die Latenz für grundlegende GET/SET-Operationen gemessen, indem wir die Nutzlastgröße, die Batch-Größe und die Anzahl der Client-Threads variiert haben. Für unsere Durchsatzexperimente laden wir eine kleine DB (1024 Schlüssel) und eine große DB (256 Mio. Schlüssel) vorab in Garnet, bevor wir den eigentlichen Workload ausführen. Im Gegensatz dazu wurden unsere Latenzexperimente auf einer leeren Datenbank und für einen kombinierten Workload von GET/SET-Befehlen durchgeführt, die auf einem kleinen Schlüsselraum (1024 Schlüssel) operieren.
Durchsatz GET
Für das in Abbildung 1 dargestellte Experiment verwendeten wir große Batches von GET-Operationen (4096 Anfragen pro Batch) und kleine Nutzlasten (8-Byte-Schlüssel und -Werte), um den Netzwerk-Overhead zu minimieren. Wenn wir die Anzahl der Clientsitzungen erhöhen, stellen wir fest, dass **Garnet** besser skaliert als Redis oder KeyDB. Dragonfly weist ähnliche Skalierungsmerkmale auf, jedoch nur bis zu 16 Threads. Beachten Sie auch, dass DragonFly ein reines In-Memory-System ist. Insgesamt ist der Durchsatz von **Garnet** im Verhältnis zu den anderen Systemen durchweg höher, auch wenn die Datenbankgröße (d.h. die Anzahl der vorab geladenen eindeutigen Schlüssel) größer ist (bei 256 Millionen Schlüsseln) als die Größe des Prozessorspeichers.
Variieren der Anzahl von Clientsitzungen oder der Batchgröße (GET)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GET \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize $batchsize \
--dbsize $dbsize
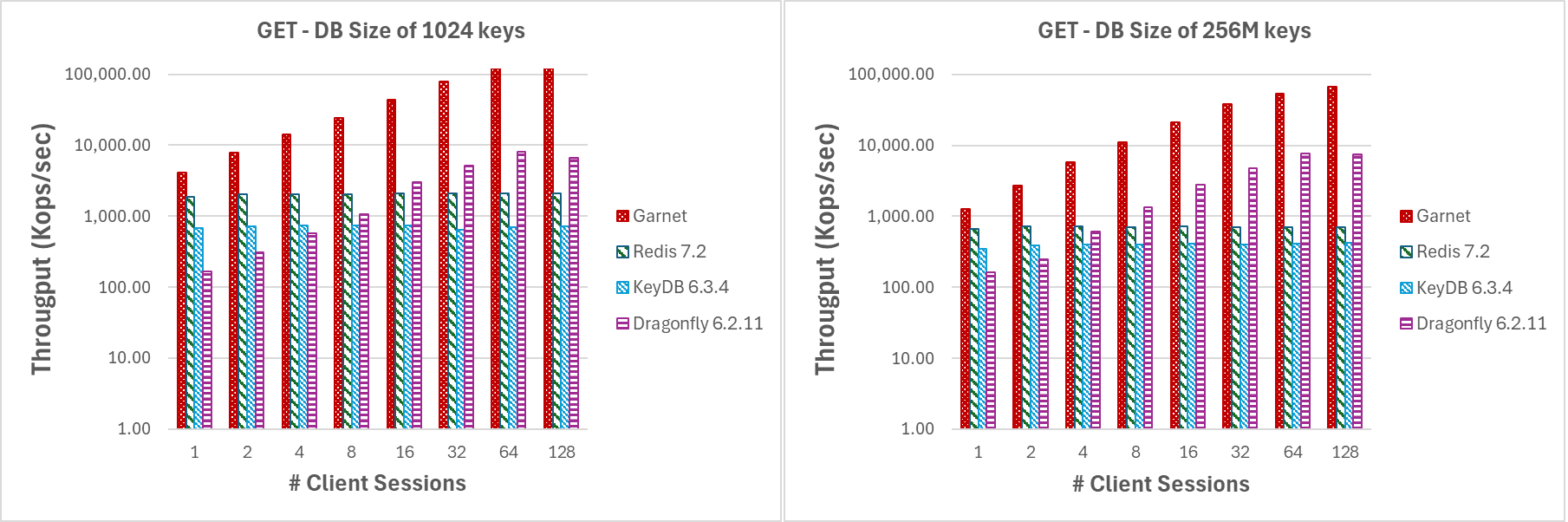 |
|---|
| Abbildung 1: Durchsatz (log-Skala), variierende Anzahl von Clientsitzungen, für eine Datenbankgröße von (a) 1024 Schlüsseln und (b) 256 Millionen Schlüsseln |
Selbst bei kleinen Batchgrößen übertrifft **Garnet** die konkurrierenden Systeme, indem es einen durchweg höheren Durchsatz erzielt, wie Abbildung 2 zeigt. Dies geschieht unabhängig von der tatsächlichen Datenbankgröße.
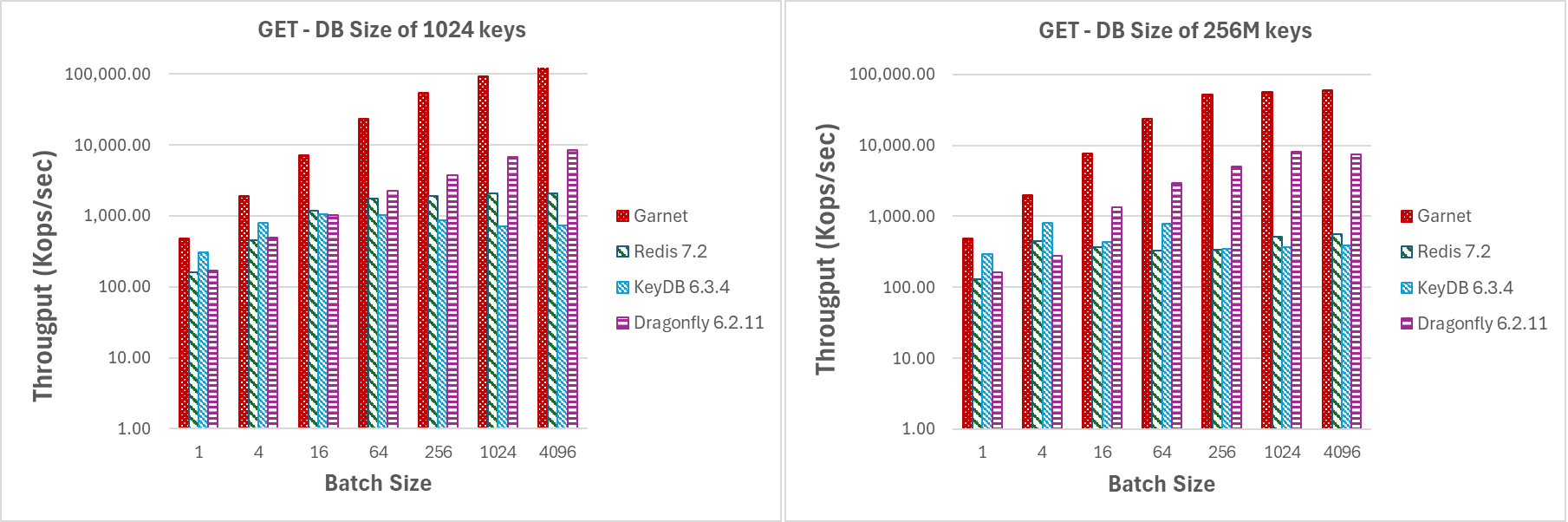 |
|---|
| Abbildung 2: Durchsatz (log-Skala), variierende Batchgrößen, für eine Datenbankgröße von (a) 1024 Schlüsseln und (b) 256 Millionen Schlüsseln |
Latenz GET/SET
Als Nächstes messen wir die Client-seitige Latenz für verschiedene Systeme, indem wir eine Mischung aus 80 % GET und 20 % SET-Anfragen ausgeben und sie mit **Garnet** vergleichen. Da uns die Latenz wichtig ist, halten wir die DB-Größe klein, während wir andere Parameter des Workloads wie Client-Threads, Batch-Größe und Nutzlastgröße variieren.
Abbildung 3 zeigt, dass Garnets Latenz (gemessen in Mikrosekunden) und über verschiedene Perzentile hinweg konsistent niedriger und stabiler ist im Vergleich zu anderen Systemen, wenn die Anzahl der Clientsitzungen steigt. Beachten Sie, dass dieses Experiment keine Batch-Verarbeitung nutzt.
Latenz-Benchmark mit variierenden Clientsitzungen oder Batchgrößen (GET/SET)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark
--host $host \
--port $port \
--batchsize 1 \
--threads $threads \
--client GarnetClientSession \
--runtime 35 \
--op-workload GET,SET \
--op-percent 80,20 \
--online \
--valuelength $valuelength \
--keylength $keylength \
--dbsize 1024 \
--itp $batchsize
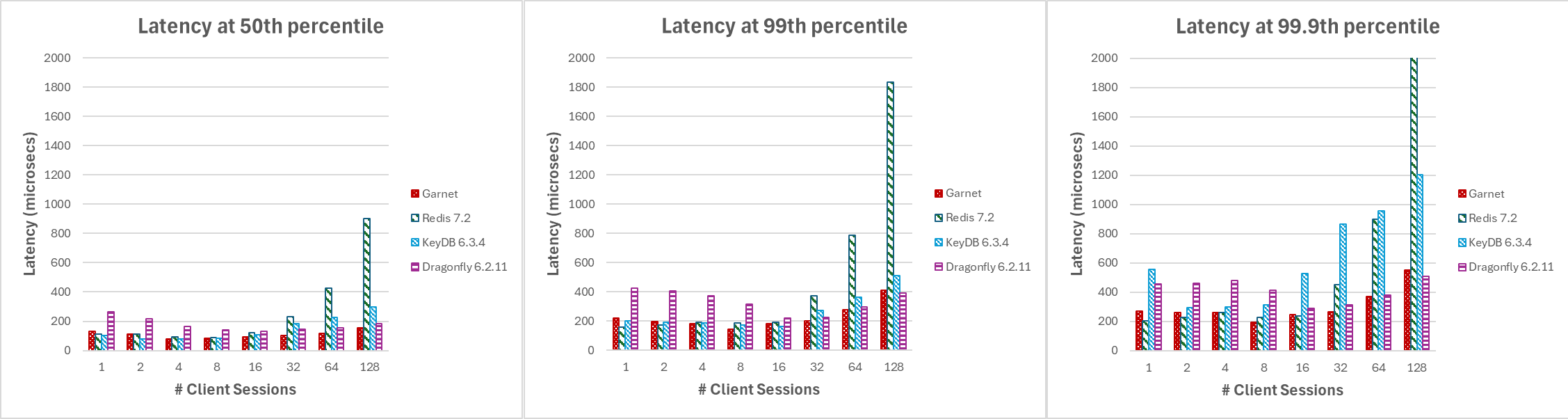 |
|---|
| Abbildung 3: Latenz, variierende Anzahl von Clientsitzungen, bei (a) Median, (b) 99. Perzentil und (c) 99,9. Perzentil |
Garnets Latenz ist für adaptives Client-seitiges Batching und effizientes Handling mehrerer Sitzungen, die das System abfragen, feinabgestimmt. Für unsere nächste Reihe von Experimenten erhöhen wir die Batchgrößen von 1 auf 64 und stellen unten die Latenz bei verschiedenen Perzentilen mit 128 aktiven Client-Verbindungen dar. Wie in Abbildung 4 dargestellt, behält **Garnet** die Stabilität bei und erzielt eine insgesamt niedrigere Latenz im Vergleich zu anderen Systemen, wenn die Batchgröße erhöht wird.
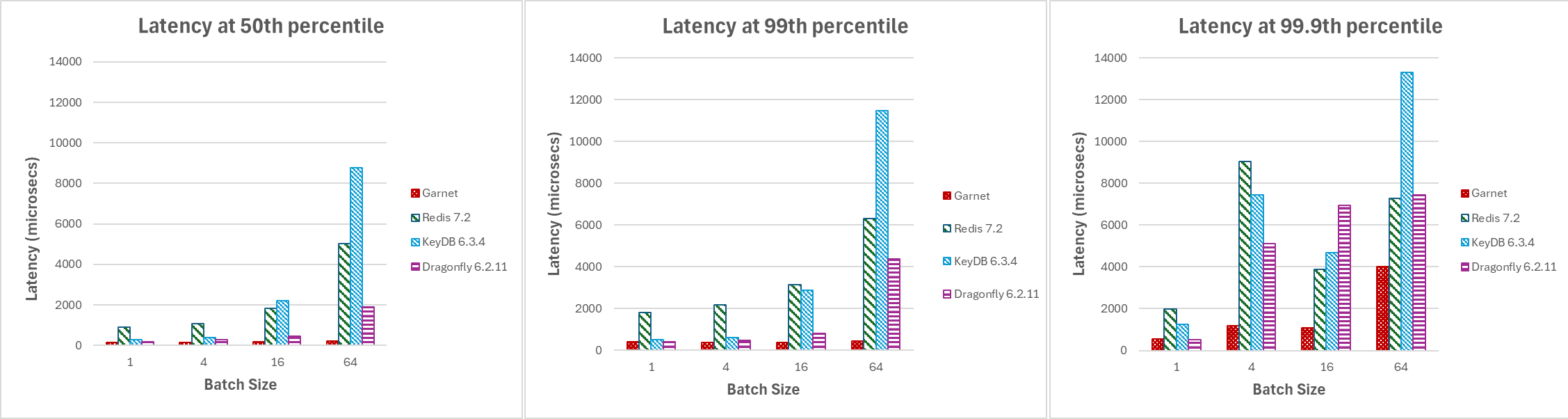 |
|---|
| Abbildung 4: Latenz, variierende Batchgrößen, bei (a) Median, (b) 99. Perzentil und (c) 99,9. Perzentil |
Leistung komplexer Datenstrukturen
**Garnet** unterstützt eine Vielzahl von komplexen Datenstrukturen wie Hyperloglog, Bitmap, Sorted Sets, Listen usw. Nachfolgend präsentieren wir Leistungskennzahlen für einige ausgewählte.
Hyperloglog
**Garnet** unterstützt seine eigene integrierte Hyperloglog (HLL)-Datenstruktur. Diese ist in C# implementiert und unterstützt Operationen wie Update (PFADD), Schätzung (PFCOUNT) und Zusammenführen (PFMERGE) von zwei oder mehr eindeutigen HLL-Strukturen. HLL-Datenstrukturen sind oft hinsichtlich ihres Speicher-Footprints optimiert. Unsere Implementierung ist da keine Ausnahme und verwendet eine Sparse-Darstellung, wenn die Anzahl der Nicht-Null-Zählungen gering ist, und eine Dense-Darstellung über einem bestimmten festen Schwellenwert hinaus, bei dem der Kompromiss zwischen Speicherersparnis und dem zusätzlichen Aufwand für die Dekompression nicht mehr attraktiv ist. Die effiziente Aktualisierung der HyperLogLog (HLL)-Struktur ist für konkurrierende Systeme wie Garnet unerlässlich. Aus diesem Grund konzentrieren sich unsere Experimente speziell auf die Leistung von PFADD und sind bewusst darauf ausgelegt, unser System für die folgenden Szenarien zu belasten
- Große Anzahl von High-Contention-Updates (d.h. Batchgröße 4096, DB mit 1024 Schlüsseln) für steigende Thread-Anzahl oder steigende Nutzlastgröße. Nach einigen Einfügungen werden die konstruierten HyperLogLog (HLL)-Strukturen zur Verwendung der Dense-Darstellung übergehen.
- Große Anzahl von Low-Contention-Updates (d.h. Batchgröße 4096, DB mit 256 Mio. Schlüsseln) für steigende Thread-Anzahl oder steigende Nutzlastgröße. Diese Anpassung erhöht die Wahrscheinlichkeit, dass die konstruierten HyperLogLog (HLL)-Strukturen die Sparse-Darstellung verwenden. Folglich werden unsere Messungen den zusätzlichen Overhead bei der Arbeit mit komprimierten Daten oder der inkrementellen Zuweisung von mehr Speicher für Nicht-Null-Werte berücksichtigen.
In Abbildung 5 präsentieren wir die Ergebnisse für das erste experimentelle Szenario. **Garnet** skaliert unter hoher Konkurrenz sehr gut und übertrifft durchweg jedes andere System in Bezug auf den reinen Durchsatz bei steigender Thread-Anzahl. Ebenso zeigt **Garnet** bei steigender Nutzlastgröße einen höheren Gesamtdurchsatz im Vergleich zu anderen Systemen. Bei allen getesteten Systemen stellten wir einen merklichen Rückgang des Durchsatzes fest, als die Nutzlastgröße zunahm. Dieses Verhalten ist aufgrund des inhärenten TCP-Netzwerk-Bottlenecks zu erwarten.
Variieren der Anzahl von Clientsitzungen oder der Nutzlastgröße bei gleichzeitiger Arbeit mit wenigen Schlüsseln
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op PFADD \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1024 \
--skipload
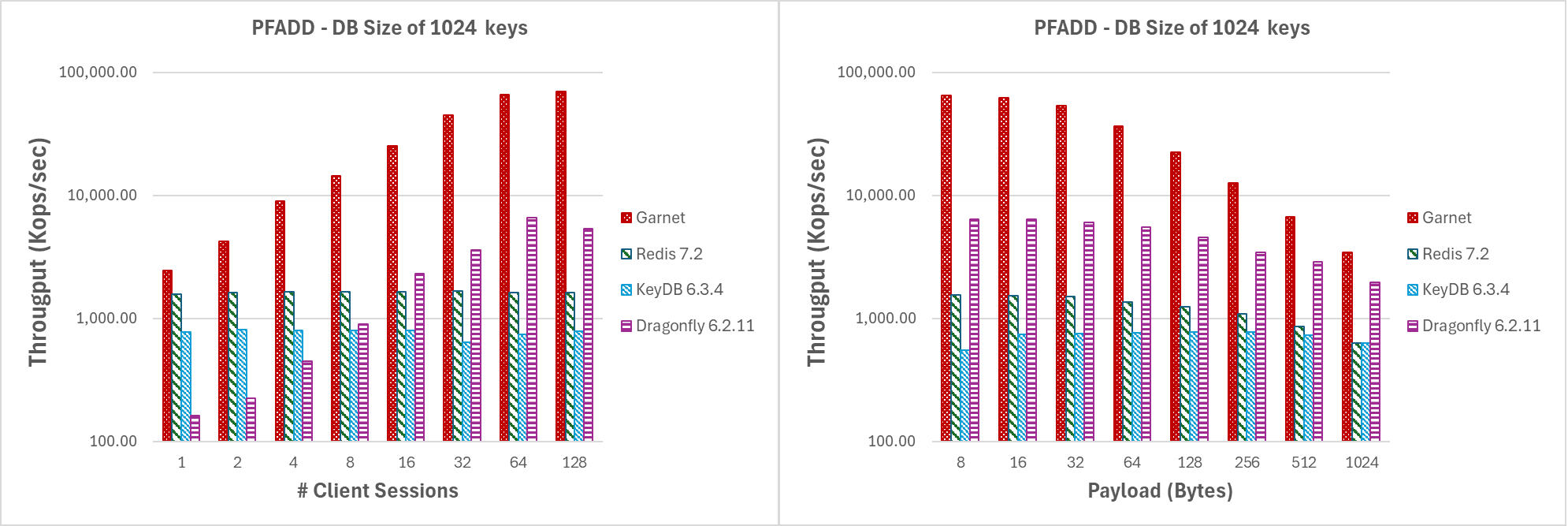 |
|---|
| Abbildung 5: Durchsatz (log-Skala) für (a) steigende Anzahl von Clientsitzungen und (b) steigende Nutzlastgröße, für eine Datenbankgröße von 1024 Schlüsseln. |
Abbildung 6 zeigt die Ergebnisse für das zweite experimentelle Szenario wie oben beschrieben. Selbst bei der Arbeit mit der HLL-Sparse-Darstellung erzielt **Garnet** bessere Leistungen als jedes andere System und erreicht durchweg höheren Durchsatz, während es bei steigender Anzahl von Clientsitzungen sehr gut skaliert. Ebenso übertrifft **Garnet** bei steigender Nutzlastgröße die Konkurrenz, indem es insgesamt einen höheren Durchsatz erzielt. Beachten Sie, dass der Durchsatz in beiden Fällen niedriger ist als im vorherigen Experiment aufgrund des Overheads bei der Arbeit mit komprimierten Daten.
Variieren der Anzahl von Clientsitzungen oder der Nutzlastgröße bei gleichzeitiger Arbeit mit vielen Schlüsseln (PFADD)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op PFADD \
--keylength 8 \
--valuelength $valuelength \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1048576 \
--totalops 1048576 \
--skipload
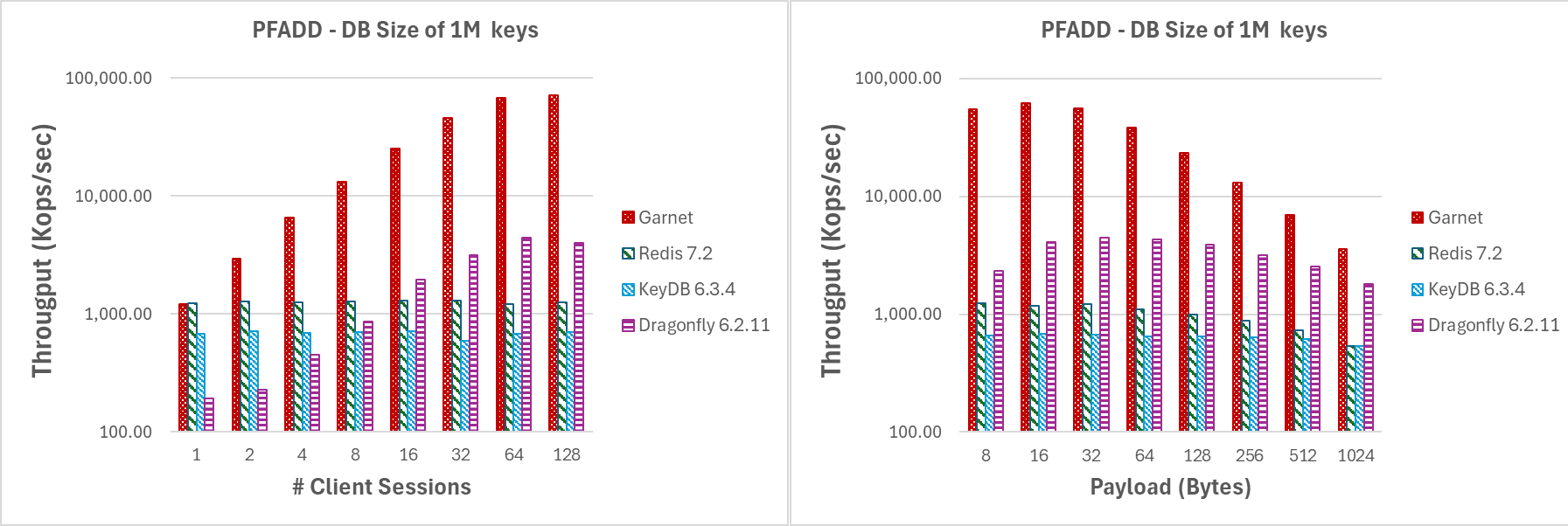 |
|---|
| Abbildung 6: Durchsatz (log-Skala) für (a) steigende Anzahl von Clientsitzungen und (b) steigende Nutzlastgröße, für eine Datenbankgröße von 1 Mio. Schlüsseln. |
In Abbildung 7 führen wir die gleiche Art von Experiment durch wie zuvor, indem wir die Anzahl der Clientsitzungen auf 64 und die Nutzlast auf 128 Bytes festlegen, während wir die Batchgröße erhöhen. Beachten Sie, dass selbst bei einer Batchgröße von 4 die Durchsatzgewinne von **Garnet** merklich höher sind als bei jedem anderen von uns getesteten System. Dies zeigt, dass wir selbst bei kleinen Batchgrößen die konkurrierenden Systeme übertreffen.
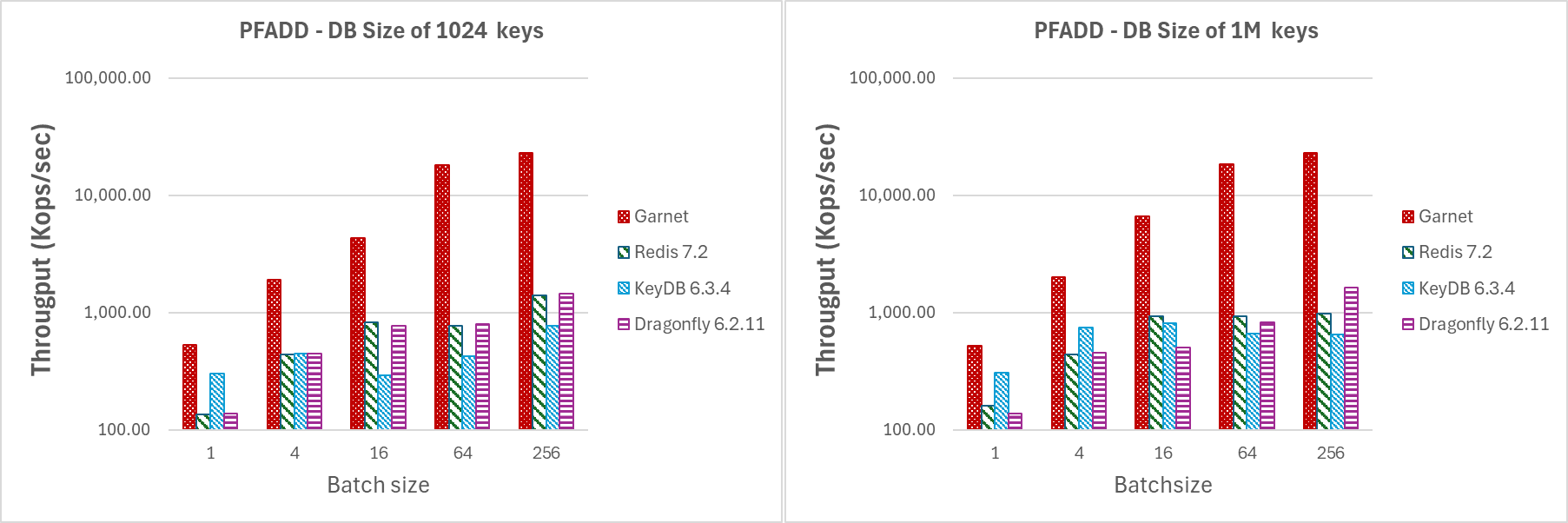 |
|---|
| Abbildung 7: Durchsatz (log-Skala) für steigende Batchgrößen mit 64 Clientsitzungen auf einer DB mit (a) 1024 Schlüsseln, (b) 1 Mio. Schlüsseln. |
Bitmap
**Garnet** unterstützt eine Reihe von bitorientierten Operatoren für String-Datentypen. Diese Operatoren können in konstanter Zeit (d.h. GETBIT, SETBIT) oder linearer Zeit (d.h. BITCOUNT, BITPOS, BITOP) verarbeitet werden. Um die Verarbeitung zu beschleunigen, haben wir für die linearen Operatoren Hardware- und SIMD-Instruktionen verwendet. Nachfolgend präsentieren wir die Benchmark-Ergebnisse für eine Teilmenge dieser Operatoren, die beide Komplexitätskategorien abdecken. Ähnlich wie zuvor verwenden wir eine kleine DB-Größe (1024 Schlüssel), um die Leistung jedes Systems unter hoher Konkurrenz zu bewerten, während wir durch Erhöhung der Nutzlastgröße (1 MB) verhindern, dass alle Daten im CPU-Cache verbleiben.
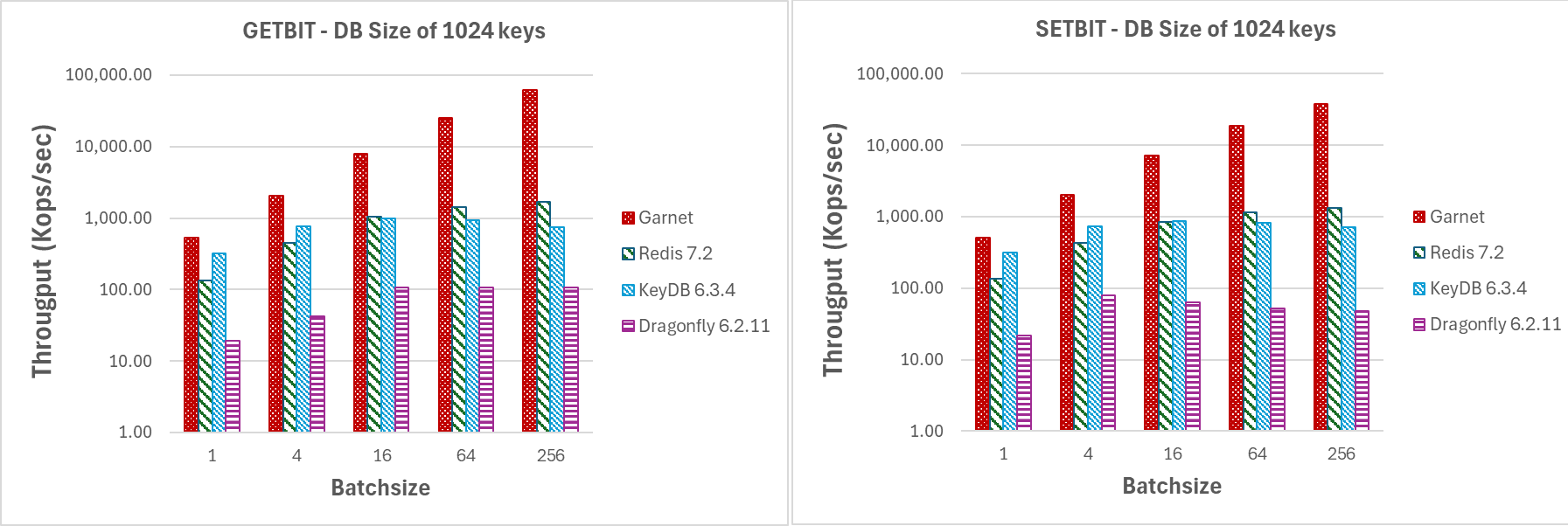
In Abbildung 8 präsentieren wir die Leistungskennzahlen für GETBIT- und SETBIT-Befehle. In beiden Fällen behält **Garnet** durchweg einen höheren Durchsatz und eine bessere Skalierbarkeit bei, wenn die Anzahl der Clientsitzungen steigt.
Variieren der Anzahl von Clientsitzungen (GETBIT/SETBIT/BITOP_NOT/BITOP_AND)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GETBIT \
--keylength 8 \
--valuelength 1048576 \
--threads 1,2,4,8,16,32,64,128 \
--batchsize 4096 \
--dbsize 1024
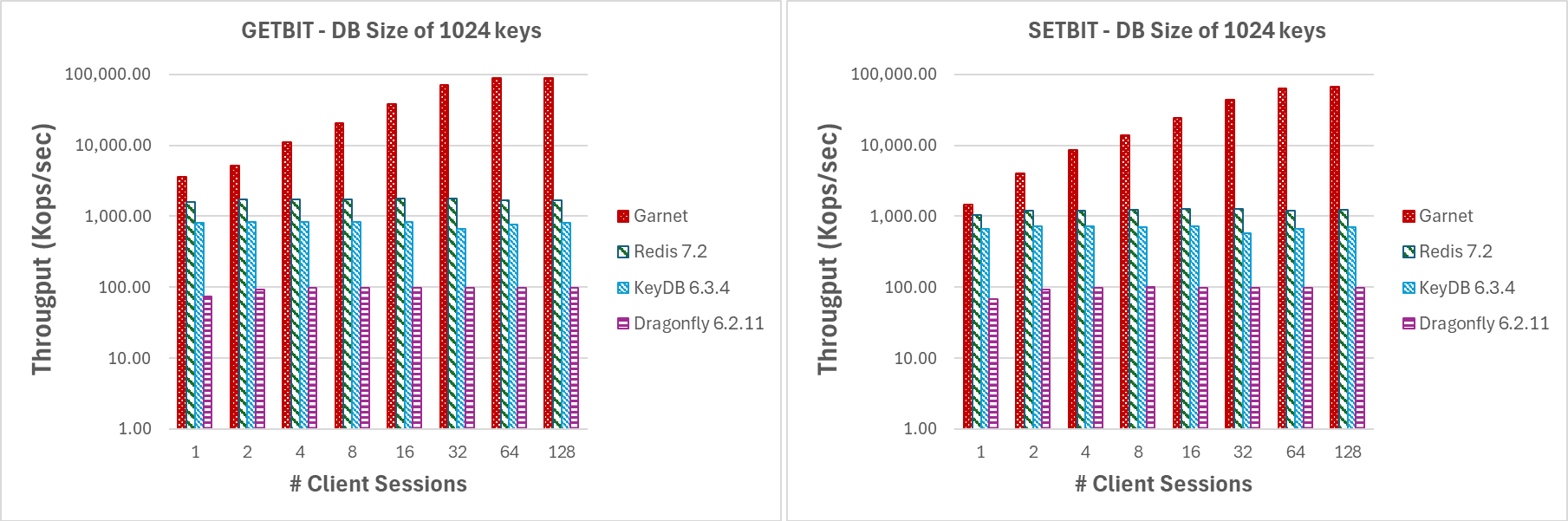 |
|---|
| Abbildung 8: Durchsatz (log-Skala), variierende Anzahl von Clientsitzungen, für eine Datenbankgröße von 1024 Schlüsseln und 1 MB Nutzlast. |
In Abbildung 9 bewerten wir die Leistung von BITOP NOT und BITOP AND (mit zwei Quellschlüsseln) für steigende Thread-Anzahl und eine Nutzlastgröße von 1 MB. **Garnet** behält im Vergleich zu jedem anderen von uns getesteten System einen insgesamt höheren Durchsatz bei, wenn die Anzahl der Clientsitzungen steigt. Es leistet auch unter hoher Konkurrenz sehr gute Ergebnisse, da unsere DB-Größe relativ klein ist (d.h. nur 1024 Schlüssel).
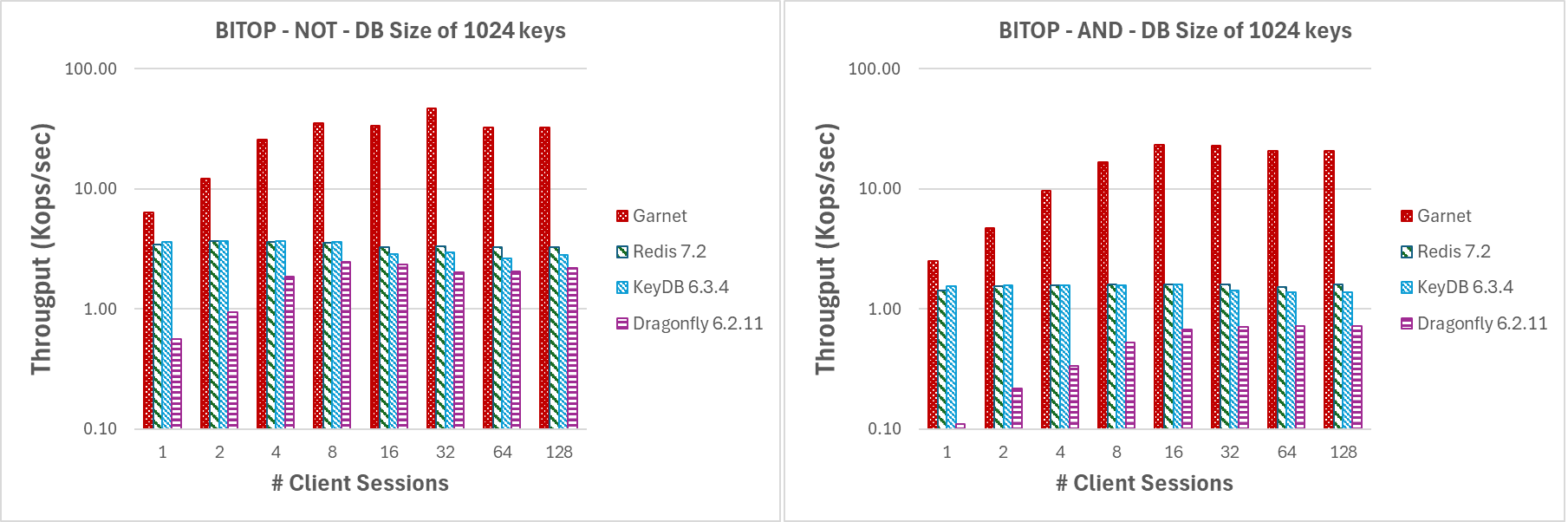 |
|---|
| Abbildung 9: Durchsatz (log-Skala), variierende Anzahl von Clientsitzungen, für eine Datenbankgröße von 1024 Schlüsseln und 1 MB Nutzlast. |
Wie in den Abbildungen 10 und 11 gezeigt, erzielt **Garnet** selbst bei kleinen Batchgrößen einen höheren Durchsatz als jedes andere von uns getestete System für die zugehörigen Bitmap-Operationen. Tatsächlich beobachten wir mit **Garnet** einen deutlich höheren Durchsatz, selbst bei einer kleinen Batchgröße von 4.
Variieren der Batchgröße (GETBIT/SETBIT/BITOP_NOT/BITOP_AND)
dotnet run -c Release --framework=net8.0 --project Garnet/benchmark/Resp.benchmark \
--host $host \
--port $port \
--op GETBIT \
--keylength 8 \
--valuelength 1048576 \
--threads 64 \
--batchsize $batchsize \
--dbsize 1024
 |
|---|
| Abbildung 10: Durchsatz (log-Skala) für steigende Batchgrößen mit 64 Clientsitzungen auf einer DB mit 1024 Schlüsseln und 1 MB Nutzlast. |
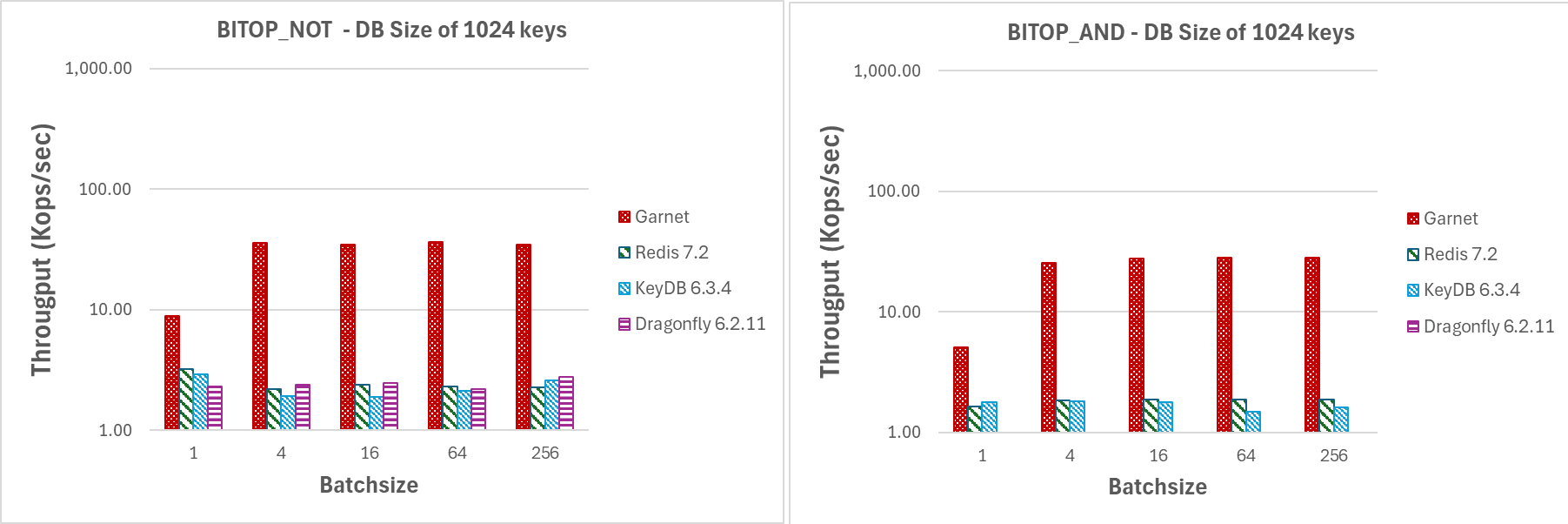 |
|---|
| Abbildung 11: Durchsatz (log-Skala) für steigende Batchgrößen mit 64 Clientsitzungen auf einer DB mit 1024 Schlüsseln und 1 MB Nutzlast. |