Objekterkennung
Häufig gestellte Fragen
Dieses Dokument versucht, häufig gestellte Fragen zur Objekterkennung zu beantworten. Für allgemeine Fragen zum maschinellen Lernen, wie z. B. "Wie viele Trainingsbeispiele benötige ich?" oder "Wie überwache ich die GPU-Auslastung während des Trainings?", siehe auch die FAQ zur Bildklassifizierung.
- Allgemeines
- Daten
- Technologie
- Training
Allgemeines
Warum Torchvision?
Torchvision hat eine große aktive Benutzerbasis, daher ist seine Implementierung zur Objekterkennung einfach zu bedienen, gut getestet und verwendet modernste Technologie, die sich in der Community bewährt hat. Aus diesen Gründen haben wir uns entschieden, Torchvision als unsere Bibliothek für die Objekterkennung zu verwenden. Für fortgeschrittene Benutzer, die mit der neuesten Spitzentechnologie experimentieren möchten, empfehlen wir, mit unseren Torchvision-Notebooks zu beginnen und sich dann auch mit forschungsintensiveren Implementierungen wie dem Repository mmdetection zu befassen.
Daten
Wie annotiert man Bilder?
Für das Training und die Auswertung eines Objektdetektors sind annotierte Objektpositionen erforderlich. Eine der besten Open-Source-UIs, die unter Windows und Linux läuft, ist VOTT. Ein weiteres gutes Werkzeug ist LabelImg.
VOTT kann verwendet werden, um manuell Rechtecke um ein oder mehrere Objekte in einem Bild zu zeichnen. Diese Annotationen können dann im Pascal-VOC-Format (eine XML-Datei pro Bild) exportiert werden, das die bereitgestellten Notebooks lesen können.
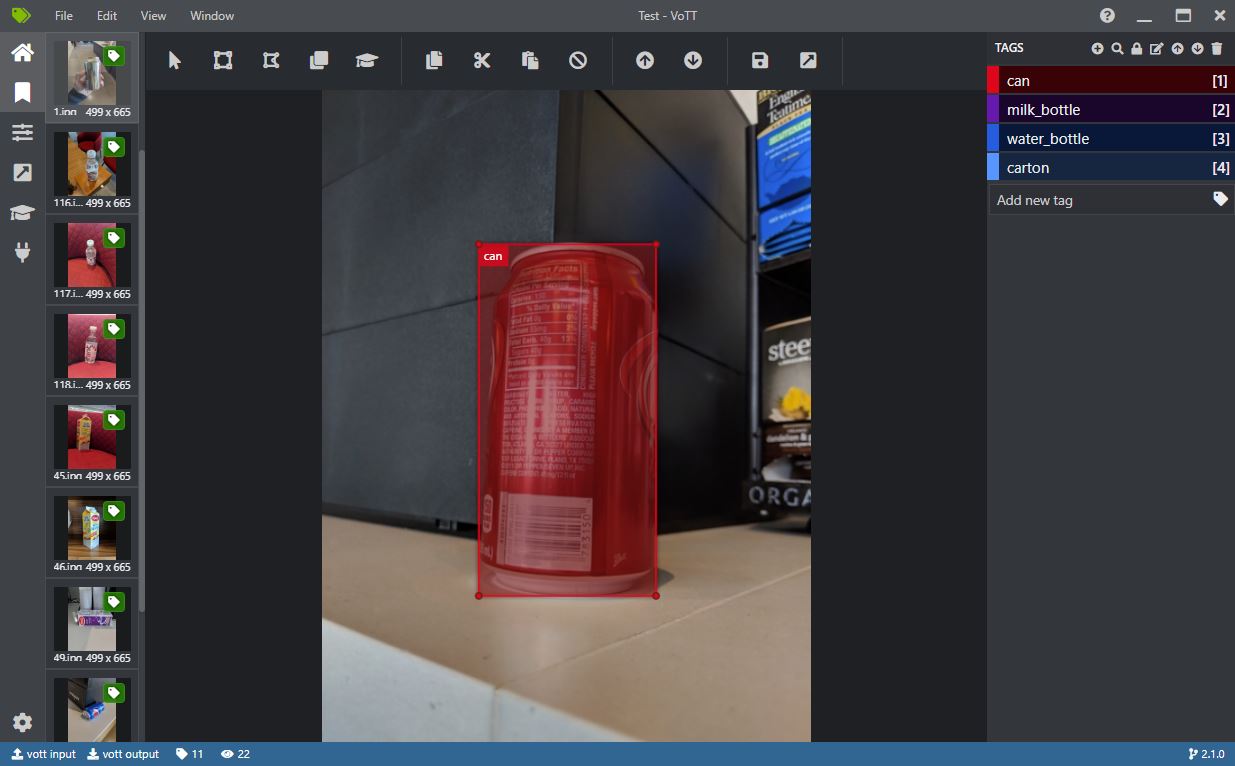
Beim Erstellen eines neuen Projekts in VOTT beachten Sie, dass die "Source Connection" einfach auf einen lokalen Ordner zeigen kann, der die zu annotierenden Bilder enthält, und die "Target Connection" entsprechend auf einen Ordner, in den die Ausgabe geschrieben werden soll. Annotationen im Pascal VOC-Stil können exportiert werden, indem "Pascal VOC" im Tab "Export Settings" ausgewählt und dann die Schaltfläche "Export Project" im Tab "Tags Editor" verwendet wird.
Für die Masken- (Segmentierungs-) Annotation ist ein einfach zu bedienendes Online-Tool Labelbox, wie in der folgenden Abbildung gezeigt. Sehen Sie sich die Demo Introducing Image Segmentation at Labelbox an, wie das Tool verwendet wird, und das Notebook 02_mask_rcnn, wie die Labelbox-Annotationen in das Pascal-VOC-Format konvertiert werden. Alternativen zu Labelbox sind CVAT oder RectLabel (nur Mac).
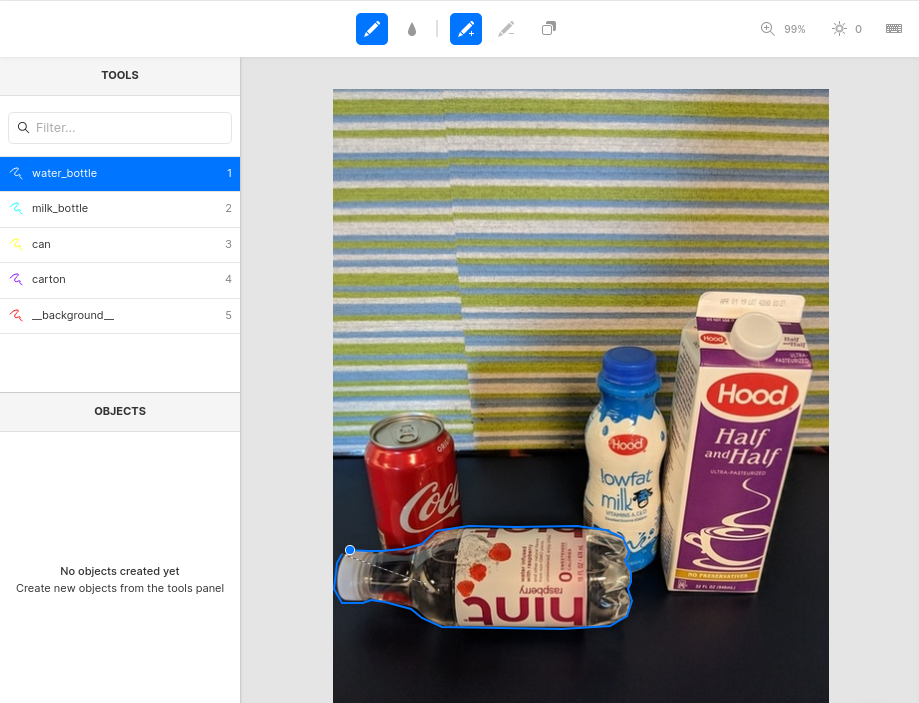
Neben dem Zeichnen von Masken kann Labelbox auch zur Annotation von Keypoints verwendet werden.
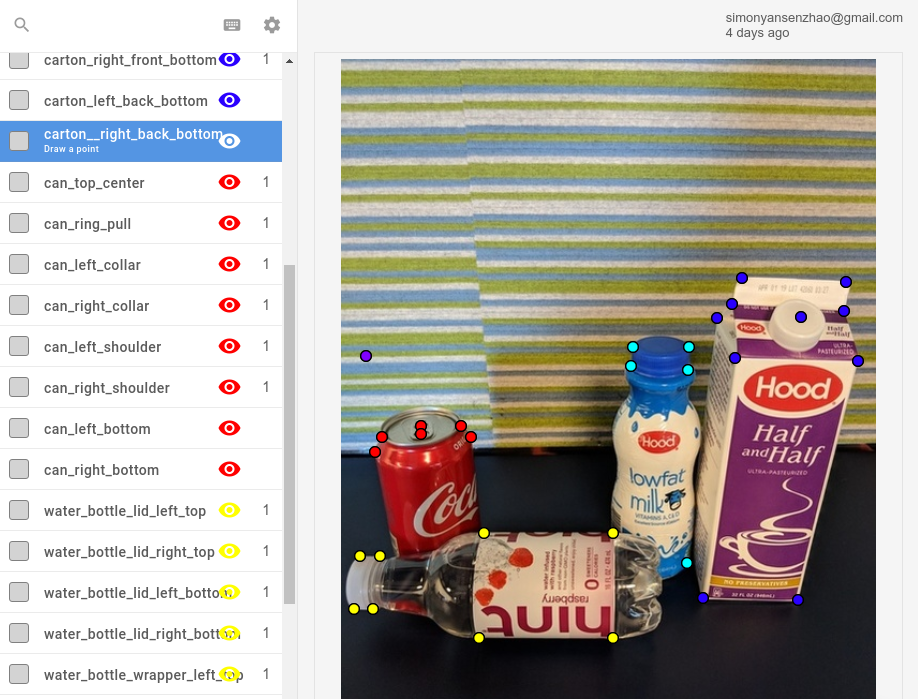
Die Auswahl und Annotation von Bildern ist komplex und Konsistenz ist entscheidend. Zum Beispiel:
- Alle Objekte in einem Bild müssen annotiert werden, auch wenn das Bild viele davon enthält. Erwägen Sie, das Bild zu entfernen, wenn dies zu viel Zeit in Anspruch nehmen würde.
- Mehrdeutige Bilder sollten entfernt werden, z. B. wenn für einen Menschen unklar ist, ob ein Objekt eine Zitrone oder ein Tennisball ist, oder wenn das Bild verschwommen ist.
- Verdeckte Objekte sollten entweder immer oder nie annotiert werden.
- Die Sicherstellung der Konsistenz ist besonders schwierig, wenn mehrere Personen beteiligt sind. Daher empfehlen wir, wenn möglich, dass die Person, die das Modell trainiert, alle Bilder annotiert. Dies hilft auch dabei, ein besseres Verständnis des Problembereichs zu erlangen.
Insbesondere der für die Auswertung verwendete Testdatensatz sollte eine hohe Annotationsqualität aufweisen, damit die Genauigkeitsmessungen die tatsächliche Leistung des Modells widerspiegeln. Der Trainingsdatensatz kann, sollte aber idealerweise nicht, verrauscht sein.
Technologie
Wie funktioniert die Technologie?
Modernste Objekterkennungsmethoden, wie sie in diesem Repository verwendet werden, basieren auf Convolutional Neural Networks (CNNs), die sich gut für Bilddaten eignen. Die meisten dieser Methoden verwenden ein CNN als Backbone, das auf Millionen von Bildern vortrainiert wurde (typischerweise unter Verwendung des ImageNet-Datensatzes). Ein solches vortrainiertes Modell wird dann in eine Objekterkennungspipeline integriert und kann mit nur wenigen annotierten Bildern feinabgestimmt werden. Eine detailliertere Erklärung des "Fine-Tunings" einschließlich Codebeispielen finden Sie im Ordner classification.
R-CNN-Ansätze zur Objekterkennung
R-CNNs zur Objekterkennung wurden 2014 von Ross Girshick et al. eingeführt und übertrafen auf einer der wichtigsten Herausforderungen der Objekterkennung, Pascal VOC, die vorherigen State-of-the-Art-Ansätze. Der Hauptnachteil des Ansatzes war seine langsame Inferenzgeschwindigkeit. Seitdem wurden drei wichtige Folgearbeiten veröffentlicht, die signifikante Geschwindigkeitsverbesserungen einführten: Fast R-CNN und Faster R-CNN und Mask R-CNN.
Ähnlich wie die meisten Methoden zur Objekterkennung verwenden R-CNNs ein tiefes neuronales Netz, das für die Bildklassifizierung mit Millionen von annotierten Bildern trainiert wurde, und modifizieren es für den Zweck der Objekterkennung. Die Grundidee des ersten R-CNN-Papiers ist in der folgenden Abbildung (aus dem Papier übernommen) dargestellt.
- Gegeben ein Eingabebild
- Eine große Anzahl von Regions-Vorschlägen, auch Regions-of-Interest (ROIs) genannt, werden generiert.
- Diese ROIs werden dann unabhängig voneinander durch das Netzwerk geleitet, das für jede ROI einen Vektor von z. B. 4096 Gleitkommawerten ausgibt.
- Schließlich wird ein Klassifikator gelernt, der die 4096 Float-ROI-Repräsentation als Eingabe nimmt und jeder ROI ein Label und eine Konfidenz zuordnet.
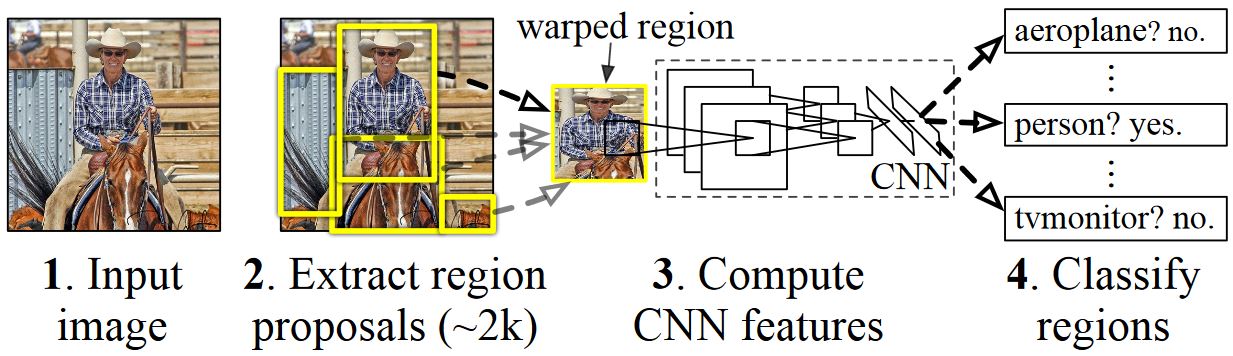
Während dieser Ansatz in Bezug auf die Genauigkeit gut funktioniert, ist er sehr rechenintensiv, da das neuronale Netz für jede ROI ausgewertet werden muss. Fast R-CNN behebt diesen Nachteil, indem es nur den größten Teil des Netzwerks (genauer gesagt: die Faltungsschichten) nur einmal pro Bild auswertet. Laut den Autoren führt dies zu einer 213-fachen Beschleunigung während der Inferenz und einer 9-fachen Beschleunigung während des Trainings ohne Genauigkeitsverlust. Faster R-CNN zeigt dann, wie ROIs als Teil des Netzwerks berechnet werden können, wodurch im Wesentlichen alle Schritte in der obigen Abbildung zu einem einzigen DNN kombiniert werden.
Intersection-over-Union Überlappungsmetrik
Es ist oft notwendig zu messen, wie stark sich zwei gegebene Rechtecke überlappen. Zum Beispiel könnte ein Rechteck der Ground-Truth-Position eines Objekts entsprechen, während das zweite Rechteck der geschätzten Position entspricht, und das Ziel ist es, zu messen, wie präzise das Objekt erkannt wurde.
Dazu wird typischerweise eine Metrik namens Intersection-over-Union (IoU) verwendet. Im folgenden Beispiel wird die IoU durch Division der gelben Fläche durch die Summe der gelben und blauen Flächen angegeben. Eine IoU von 1,0 entspricht einer perfekten Übereinstimmung, während eine IoU von 0 anzeigt, dass sich die beiden Rechtecke nicht überlappen. Typischerweise wird eine IoU von 0,5 als gute Lokalisierung betrachtet. Siehe auch diese Seite für eine eingehendere Diskussion.

Non-Maxima Suppression
Methoden zur Objekterkennung geben oft mehrere Erkennungen aus, die dasselbe Objekt in einem Bild ganz oder teilweise abdecken. Diese Erkennungen müssen bereinigt werden, um Objekte zählen und ihre genauen Positionen ermitteln zu können. Dies geschieht traditionell mit einer Technik namens Non-Maxima Suppression (NMS) und wird durch iteratives Auswählen der Erkennung mit der höchsten Konfidenz und Entfernen aller anderen Erkennungen, die (i) als zur gleichen Klasse gehörend klassifiziert werden und (ii) eine signifikante Überlappung aufweisen, gemessen mit der Intersection-over-Union (IOU)-Metrik, implementiert.
Erkennungsergebnisse mit Konfidenzwerten vor (links) und nach Non-Maxima Suppression mit IOU-Schwellenwerten von (Mitte) 0,8 und (rechts) 0,5.

Mean Average Precision
Nach dem Training kann die Qualität des Modells anhand verschiedener Kriterien wie Präzision, Recall, Genauigkeit, Fläche unter der Kurve usw. gemessen werden. Eine gängige Metrik, die für die Pascal VOC-Objekterkennungs-Challenge verwendet wird, ist die Messung der Average Precision (AP) für jede Klasse. Average Precision berücksichtigt die Konfidenz bei den Erkennungen und bestraft daher falsch positive Erkennungen mit geringer Konfidenz weniger. Eine Beschreibung der Average Precision finden Sie bei Everingham et. al. Die Mean Average Precision (mAP) wird dann durch Mittelung über alle APs berechnet.
Training
Wie kann die Genauigkeit verbessert werden?
Eine Möglichkeit, die Genauigkeit zu verbessern, ist die Optimierung der Modellarchitektur oder des Trainingsverfahrens. Die folgenden Parameter haben tendenziell den größten Einfluss auf die Genauigkeit:
- Bildauflösung: Erhöhen Sie auf z. B. 1200 Pixel Eingabeauflösung, indem Sie
IM_SIZE = 1200setzen. - Anzahl der Vorschläge: Erhöhen Sie auf z. B. diese Werte:
rpn_pre_nms_top_n_train = rpn_post_nms_top_n_train = 10000undrpn_pre_nms_top_n_test = rpn_post_nms_top_n_test = 5000. - Lernrate und Anzahl der Epochen: Die jeweiligen Standardwerte, die z. B. im 01-Notebook angegeben sind, sollten in den meisten Fällen gut funktionieren. Man könnte jedoch etwas höhere/niedrigere Werte für die Lernrate und die Epochen ausprobieren.
Siehe auch die FAQ zur Bildklassifizierung für weitere Vorschläge zur Verbesserung der Modellgenauigkeit oder zur Erhöhung der Inferenz-/Trainingsgeschwindigkeit.