Bildklassifizierung
Häufig gestellte Fragen
- Allgemeines
- Daten
- Training
- Fehlerbehebung
Allgemeines
Wie funktioniert die Technologie?
Aktuelle Bildklassifizierungsmethoden, wie sie in diesem Repository verwendet werden, basieren auf Convolutional Neural Networks (CNNs), einer speziellen Gruppe von Deep Learning (DL)-Ansätzen, die sich gut für Bilddaten eignen.
Ein Vorteil von CNNs ist die Möglichkeit, ein CNN, das auf Millionen von Bildern trainiert wurde (typischerweise unter Verwendung des ImageNet-Datensatzes), wiederzuverwenden, indem es mit einem kleinen Datensatz feinjustiert wird, um ein maßgeschneidertes CNN zu erstellen. Der Transfer-Learning-Ansatz übertrifft traditionelle (nicht-DL) Ansätze in Bezug auf Genauigkeit, einfache Implementierung und oft auch Inferenzgeschwindigkeit bei weitem. Dieser Ansatz hat das Design von Computer Vision-Systemen mit dem AlexNet-Paper grundlegend verändert. Angesichts des Erfolgs von Transfer-Learning ist das zeitaufwendigste Element beim Aufbau einer CV-Lösung heute das Sammeln und Annotieren von Daten.
Die AlexNet DNN-Architektur (siehe unten) besteht aus 8 Schichten: 5 Convolutional-Schichten gefolgt von 3 Fully-Connected-Schichten. Frühe Schichten lernen niedrigstufige Merkmale (z. B. Linien oder Kanten), die in aufeinanderfolgenden Schichten zu immer komplexeren Konzepten (z. B. Rad oder Gesicht) kombiniert werden. Neuere Architekturen wie ResNet sind deutlich tiefer als AlexNet und können Hunderte von Schichten umfassen, wobei fortschrittlichere Techniken zur Unterstützung der Modellkonvergenz eingesetzt werden. 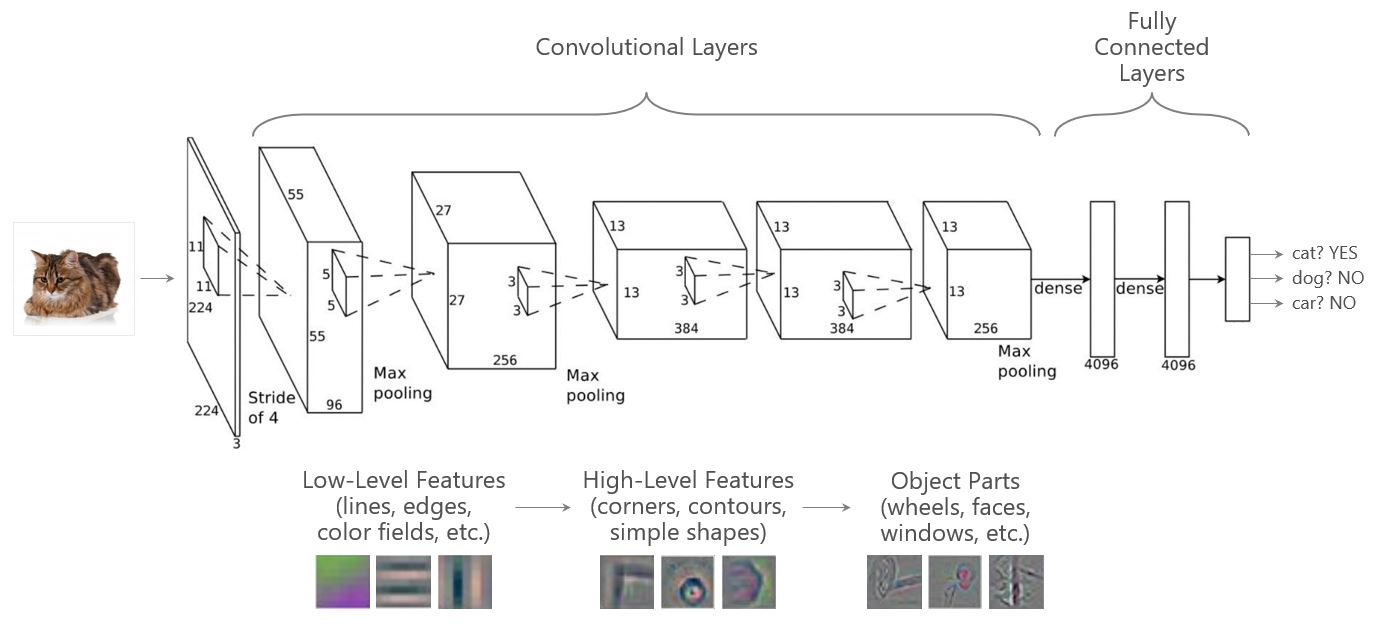
Transfer-Learning ist der aktuelle Stand der Technik für CV-Probleme. Um mit diesen Konzepten zu beginnen, empfehlen wir die folgenden Referenzen
- CNN Features off-the-shelf: an Astounding Baseline for Recognition
- A Simple Introduction to Convolutional Neural Networks
- An Intuitive Explanation of Convnets
Welche Probleme können mit Bildklassifizierung gelöst werden?
Bildklassifizierung kann verwendet werden, wenn das interessierende Objekt relativ groß im Bild ist (mehr als 20 % der Bildbreite/-höhe). Wenn das Objekt kleiner ist oder wenn der Standort des Objekts erforderlich ist, sollten stattdessen Objekterkennungsverfahren verwendet werden.
Daten
Wie viele Bilder werden zum Trainieren eines Modells benötigt?
Dies hängt stark von der Komplexität des Problems ab. Wenn sich das interessierende Objekt beispielsweise von Bild zu Bild stark unterscheidet (Blickwinkel, Lichtverhältnisse usw.), werden mehr Trainingsbilder benötigt, damit das Modell das Erscheinungsbild des Objekts lernt.
Wir haben Fälle gesehen, in denen die Verwendung von ca. 100 Bildern pro Klasse gute Ergebnisse erzielte. Der beste Ansatz, um die erforderliche Größe des Trainingsdatensatzes zu ermitteln, besteht darin, das Modell mit einer kleinen Anzahl von Bildern zu trainieren, diese Anzahl schrittweise zu erhöhen und die Modellgenauigkeitsverbesserungen auf einem festen Testdatensatz zu beobachten. Sobald die Genauigkeitsverbesserungen aufhören, sich zu ändern (konvergieren), werden mehr Trainingsbilder die Genauigkeit nicht verbessern und sind nicht erforderlich.
Wie sammelt man einen großen Satz von Bildern?
Das Sammeln einer ausreichend großen Anzahl von annotierten (gelabelten) Bildern für Training und Test kann schwierig sein. Für einige Probleme ist es möglicherweise möglich, zusätzliche Bilder aus dem Internet zu scrapen. Wir haben zum Beispiel Bing-Bilder-Suchergebnisse für die Abfrage „t-shirt striped“ verwendet. Wie erwartet, entsprachen die meisten Bilder der Abfrage für gestreifte T-Shirts, und die wenigen falschen wurden leicht identifiziert und entfernt.
| Bing Bildersuche | Cognitive Services Bildersuche |
|---|---|
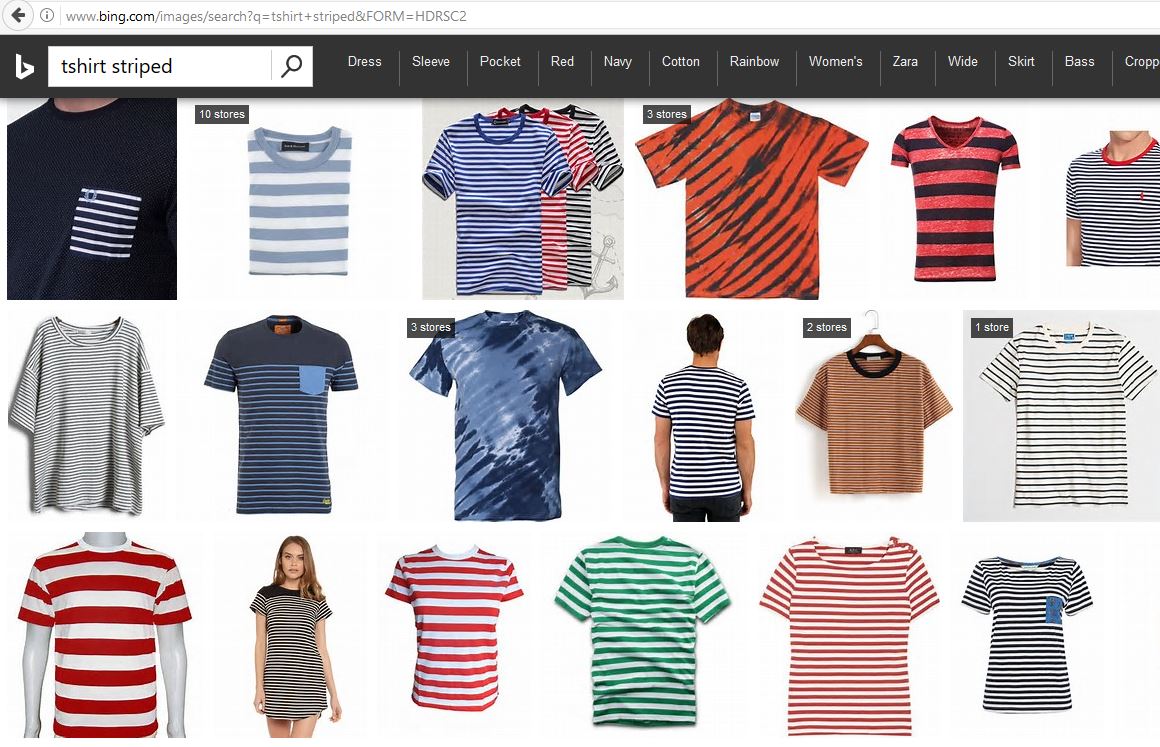 |
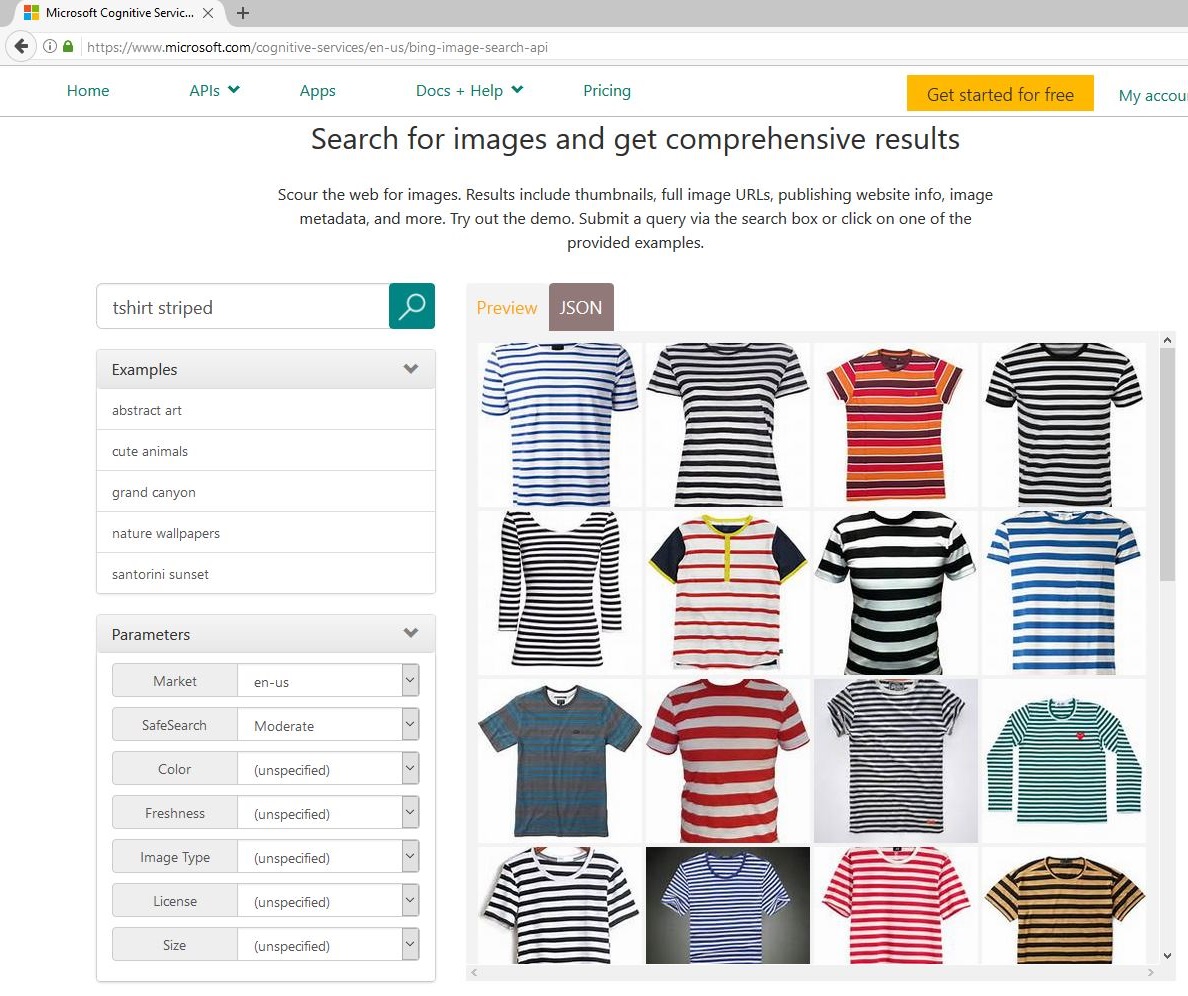 |
Alternativ zum manuellen Herunterladen von Bildern kann auch die Cognitive Services Bing Image Search API (rechtes Bild) für diesen Prozess verwendet werden. Um einen großen und vielfältigen Datensatz mit Cognitive Services zu generieren, können mehrere Abfragen verwendet werden. Zum Beispiel können 7*3 = 21 Abfragen durch Kombinationen aller 7 Kleidungsstücke {bluse, hoodie, pullover, sweater, shirt, t-shirt, weste} und 3 Attribute {gestreift, gepunktet, leopard} synthetisiert werden. Das Herunterladen der Top 50 Bilder pro Abfrage führt zu maximal 21*50=1050 Bildern.
Eine Einschränkung bei der automatischen Erweiterung Ihres Trainingsdatensatzes ist, dass einige heruntergeladene Bilder exakte oder nahezu exakte Duplikate sein können (unterschieden durch Bildauflösung oder JPG-Artefakte). Diese Bilder sollten entfernt werden, damit der Trainings- und Testdatensatz keine identischen Beispielbilder enthält. Ein zweistufiger hashing-basierter Ansatz kann helfen
- Für alle Bilder wird ein Hash-String berechnet.
- Nur Bilder mit einem eindeutigen Hash-String werden beibehalten.
Wir fanden den dhash-Ansatz aus der Python-Bibliothek imagehash (Blog) mit einem hash_size-Parameter von 16 hilfreich.
Wie augmentiert man Bilddaten?
Die Verwendung von mehr Trainingsdaten kann das Modell besser generalisieren lassen, aber die Datensammlung ist sehr teuer. Die Augmentierung der Trainingsdaten mit geringfügigen Änderungen hat sich in diesen Fällen als gut erwiesen. Dieser Ansatz erspart Ihnen das Sammeln weiterer Daten und verhindert, dass das CV-Modell überanpasst wird.
Die Methode verwendet Bildtransformationen wie Rotation, Zuschneiden und Anpassung der Helligkeit/des Kontrasts zur Augmentierung der Trainingsdaten. Diese funktionieren nicht unbedingt bei allen Problemen, können aber hilfreich sein, wenn die transformierten Bilder repräsentativ für die gesamte Bildpopulation sind, auf die das CV-Modell angewendet wird. So schadet beispielsweise in der Abbildung unten das horizontale und vertikale Spiegeln der Modellleistung bei der Zeichenerkennung, da diese Richtungen für das Modellergebnis informativ sind. Im Beispiel des Flaschenbildes verbessert das vertikale Spiegeln möglicherweise nicht die Modellgenauigkeit, aber das horizontale Spiegeln kann dies tun. Beide Richtungen sind beim Problem der Satellitenbilder hilfreich.
 Beispiele für verschiedene Bildtransformationen (Erste Reihe: MNIST, zweite Reihe: Kühlschrankobjekt, dritte Reihe: Planet)
Beispiele für verschiedene Bildtransformationen (Erste Reihe: MNIST, zweite Reihe: Kühlschrankobjekt, dritte Reihe: Planet)
Wie annotiert man Bilder?
Das Annotieren von Bildern ist komplex und teuer. Konsistenz ist entscheidend. Verdeckte Objekte sollten entweder immer oder nie annotiert werden. Mehrdeutige Bilder sollten entfernt werden, zum Beispiel wenn für einen Menschen unklar ist, ob ein Bild eine Zitrone oder ein Tennisball zeigt. Die Sicherstellung der Konsistenz ist besonders schwierig, wenn mehrere Personen beteiligt sind, und daher empfehlen wir, dass nur eine Person alle Bilder annotiert. Wenn diese Person auch das KI-Modell trainiert, unterstützt der Annotationsprozess ein besseres Verständnis der Bilder und der Komplexität der Klassifizierungsaufgabe.
Beachten Sie, dass der Testdatensatz eine hohe Annotationsqualität aufweisen sollte, um sicherzustellen, dass die Modellgenauigkeitsschätzungen zuverlässig sind.
Wie teilt man in Trainings- und Testbilder auf?
Oft ist eine zufällige Aufteilung in Ordnung, aber es gibt Ausnahmen. Wenn beispielsweise die Bilder aus einem Film extrahiert werden, würde die Aufnahme von Frame n im Trainingsdatensatz und Frame n+1 im Testdatensatz zu überhöhten Genauigkeitsschätzungen führen, da die beiden Bilder zu ähnlich sind. Darüber hinaus sollten bei einer inhärenten Klassenungleichheit in den Daten andere Kontrollen vorhanden sein, um sicherzustellen, dass alle Klassen in den Trainings- und Testdatensätzen enthalten sind.
Wie entwirft man einen guten Testdatensatz?
Der Testdatensatz sollte Bilder enthalten, die der Population ähneln, für die das Modell bewertet werden soll. Zum Beispiel Bilder, die unter ähnlichen Lichtverhältnissen, ähnlichen Winkeln usw. aufgenommen wurden. Dies trägt dazu bei, dass die Genauigkeitsschätzung die tatsächliche Leistung der Anwendung, die das trainierte Modell verwendet, widerspiegelt.
Training
Wie beschleunigt man das Training?
- Alle Bilder können auf einem lokalen SSD-Speichergerät gespeichert werden, da HDD- oder Netzwerkladezeiten die Trainingszeit dominieren können.
- Hochauflösende Bilder können das Training verlangsamen, da die JPEG-Dekodierung zum Engpass wird (>10x Leistungsverlust). Weitere Informationen finden Sie im Notebook 02_training_accuracy_vs_speed.ipynb.
- Sehr hochauflösende Bilder (>4 Megapixel) können vor dem DNN-Training verkleinert werden.
Wie verbessert man die Genauigkeit oder die Inferenzgeschwindigkeit?
Im Notebook 02_training_accuracy_vs_speed.ipynb finden Sie eine Diskussion darüber, welche Parameter wichtig sind und welche Strategien zur Auswahl eines Modells zur Optimierung der Inferenzgeschwindigkeit führen.
Wie überwacht man die GPU-Auslastung während des Trainings?
Es gibt verschiedene Tools zur Überwachung von Echtzeit-GPU-Informationen (z. B. GPU- oder Speicherauslastung). Dies ist eine unvollständige Liste der Tools, die wir verwendet haben
- GPU-Z: Hat eine einfach zu installierende Benutzeroberfläche.
- nvidia-smi: Kommandozeilen-Tool. Vorinstalliert auf der Azure Data Science VM.
- GPU monitor: Python SDK zur Überwachung von GPUs auf einer einzelnen Maschine oder über einen Cluster hinweg.
Fehlerbehebung
Widget wird nicht angezeigt
Jupyter-Widgets sind recht instabil und werden möglicherweise auf einigen Systemen nicht korrekt gerendert oder zeigen sich oft gar nicht. Versuchen Sie in diesem Fall:
- Verwendung anderer Browser
- Aktualisierung der Jupyter-Notebook-Bibliothek mit den folgenden Befehlen
# Update jupyter notebook activate cv conda upgrade notebook # Run notebook server in activated 'cv' environment activate cv jupyter notebook