Multi-Object Tracking
Häufig gestellte Fragen
Dieses Dokument enthält Antworten und Informationen zu häufig gestellten Fragen und Themen im Zusammenhang mit Multi-Object Tracking. Für allgemeinere Fragen zum maschinellen Lernen, wie z.B. „Wie viele Trainingsbeispiele benötige ich?“ oder „Wie überwache ich die GPU-Auslastung während des Trainings?“, siehe auch die FAQ zur Bildklassifizierung.
- Daten
- Training und Inferenz
- Evaluierung
- State-of-the-Art (SoTA) Technologie
- Beliebte MOT-Datensätze
- Wie ist die Architektur des FairMOT-Tracking-Algorithmus?
- Welche Objektdetektoren werden in Tracking-by-Detection-Trackern verwendet?
- Welche Feature-Extraktionstechniken werden in Tracking-by-Detection-Trackern verwendet?
- Welche Affinitäts- und Assoziationstechniken werden in Tracking-by-Detection-Trackern verwendet?
- Was ist der Unterschied zwischen Online- und Offline-(Batch-)Tracking-Algorithmen?
- [Beliebte Publikationen und Datensätze]
Daten
Wie annotiert man Bilder?
Für das Training verwenden wir dasselbe Annotationsformat wie für die Objekterkennung (siehe diese FAQ). Das bedeutet auch, dass wir von einzelnen Frames trainieren, ohne die zeitliche Position dieser Frames zu berücksichtigen.
Für die Bewertung folgen wir dem py-motmetrics Repository, das die Ground-Truth-Daten im MOT challenge Format benötigt. Die letzten 3 Spalten können standardmäßig auf -1 gesetzt werden, für den Zweck der Ground-Truth-Annotation.
[frame number] [id number] [bbox left] [bbox top] [bbox width] [bbox height][confidence score][class][visibility]
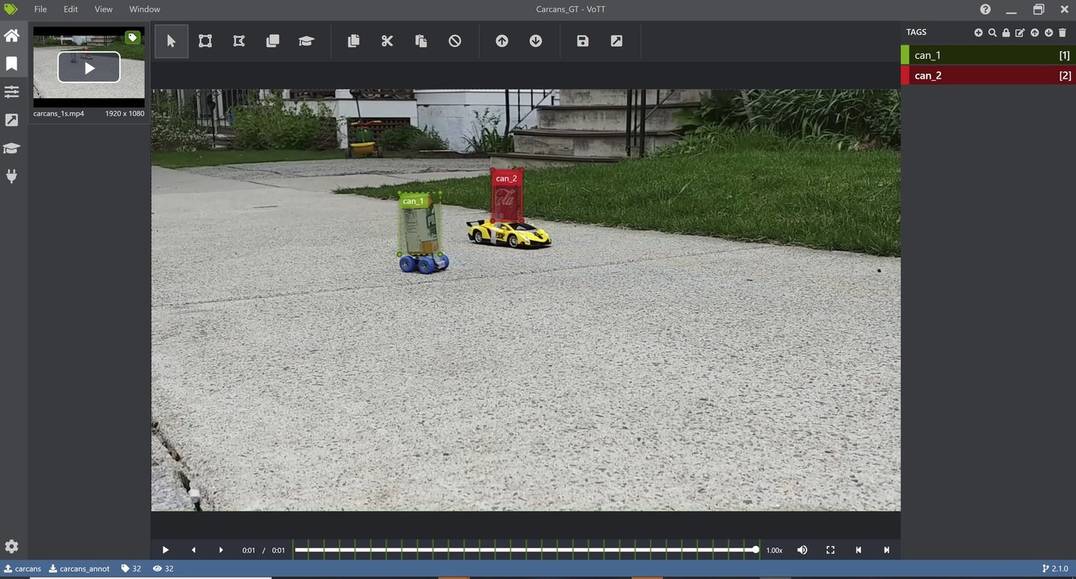
Siehe unten ein Beispiel, in dem wir VOTT verwenden, um die beiden Dosen im Bild als can_1 und can_2 zu annotieren, wobei sich can_1 auf die weiß/gelbe Dose und can_2 auf die rote Dose bezieht. Vor der Annotation ist es wichtig, die Extraktionsrate korrekt einzustellen, um der des Videos zu entsprechen. Nach der Annotation können Sie die Annotationsergebnisse in verschiedenen Formen exportieren, z.B. als PASCAL VOC oder .csv-Format. Für das .csv-Format würde VOTT die extrahierten Frames sowie eine CSV-Datei mit den Bounding-Box- und ID-Informationen zurückgeben.
[image] [xmin] [y_min] [x_max] [y_max] [label]
Intern (nicht für den Benutzer sichtbar) verwendet das FairMOT-Repository dieses Annotationsformat für das Training, bei dem jede Zeile eine Bounding Box wie folgt beschreibt, wie im Towards-Realtime-MOT Repository beschrieben.
[class] [identity] [x_center] [y_center] [width] [height]
Das Feld class ist für alle auf 0 gesetzt, da nur Single-Class-Multi-Object-Tracking derzeit vom FairMOT-Repository unterstützt wird (z.B. Dosen). Das Feld identity ist eine Ganzzahl von 0 bis num_identities - 1, die Klassennamen ganzen Zahlen zuordnet (z.B. Cola-Dose, Kaffee-Dose usw.). Die Werte von [x_center] [y_center] [width] [height] werden durch die Breite/Höhe des Bildes normalisiert und reichen von 0 bis 1.
Training und Inferenz
Was sind die Trainingsverluste in FairMOT?
Die von FairMOT generierten Verluste umfassen detektionsspezifische Verluste (z.B. hm_loss, wh_loss, off_loss) und ID-spezifische Verluste (id_loss). Der Gesamtverlust (loss) ist ein gewichteter Durchschnitt der detektionsspezifischen und ID-spezifischen Verluste, siehe die FairMOT-Paper.
Was sind die wichtigsten Inferenzparameter in FairMOT?
- input_w und input_h: Bildauflösung der Videoframes des Datensatzes
- conf_thres, nms_thres, min_box_area: diese Schwellenwerte werden verwendet, um Detektionen herauszufiltern, die nicht dem Konfidenzniveau, dem NMS-Level und der Größe gemäß den Anforderungen des Benutzers entsprechen;
- track_buffer: Wenn eine verlorene Spur für eine bestimmte Anzahl von Frames, die durch diesen Schwellenwert bestimmt wird, nicht gefunden wird, wird sie gelöscht, d.h. die ID wird nicht wiederverwendet.
Evaluierung
Was ist die MOT Challenge?
Die MOT Challenge Website hostet die gängigsten Benchmark-Datensätze für Pedestrian MOT. Es existieren verschiedene Datensätze: MOT15, MOT16/17, MOT 19/20. Diese Datensätze enthalten viele Videosequenzen mit unterschiedlichen Schwierigkeitsgraden beim Tracking und annotierten Ground Truths. Detektionen werden auch zur optionalen Nutzung durch die teilnehmenden Tracking-Algorithmen bereitgestellt.
Was sind die gängigsten Bewertungsmetriken?
Da Multi-Object-Tracking eine komplexe CV-Aufgabe ist, gibt es viele verschiedene Metriken zur Bewertung der Tracking-Leistung. Basierend auf ihrer Berechnung können Metriken ereignisbasiert sein CLEARMOT metrics oder ID-basierte Metriken. Die wichtigsten Metriken zur Erfassung der Leistung in der MOT Benchmarking Challenge sind MOTA, IDF1 und ID-switch.
- MOTA (Multiple Object Tracking Accuracy) erfasst die allgemeine Genauigkeitsleistung mit einer ereignisbasierten Berechnung, wie oft eine Fehlausrichtung zwischen den Tracking-Ergebnissen und dem Ground Truth auftritt. MOTA enthält die Zählungen von FP (False Positive), FN (False Negative) und ID-Switches (IDSW), normalisiert über die Gesamtzahl der Ground Truth (GT) Spuren.
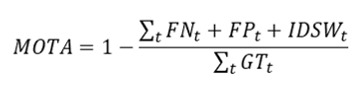
- IDF1 misst die Gesamtleistung mit einer ID-basierten Berechnung, wie lange der Tracker das Ziel korrekt identifiziert. Es ist das harmonische Mittel aus Identifikationspräzision (IDP) und Recall (IDR).

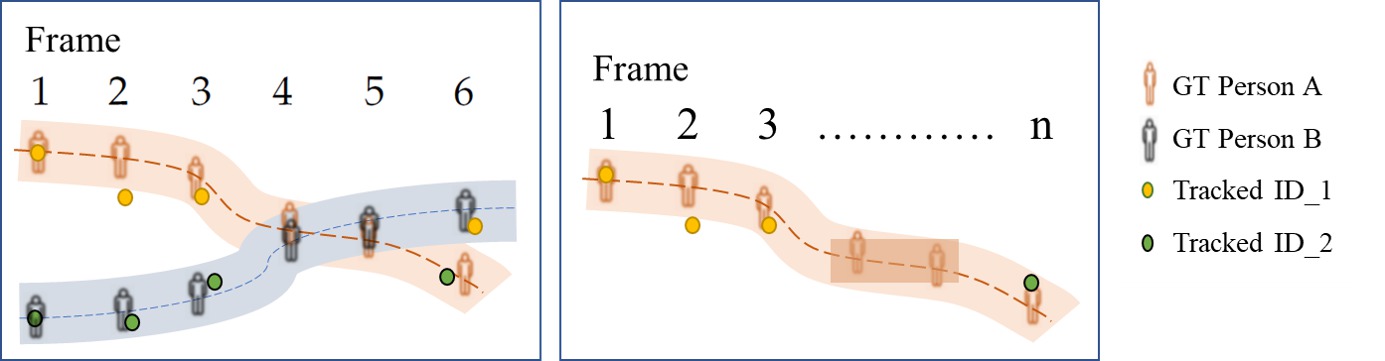
- ID-switch misst, wenn der Tracker fälschlicherweise die ID einer Trajektorie ändert. Dies wird in der folgenden Abbildung veranschaulicht: in der linken Box überlappen sich Person A und Person B und werden in den Frames 4-5 nicht erkannt und verfolgt. Dies führt zu einem ID-Switch in Frame 6, wo Person A die ID_2 zugewiesen wird, die zuvor als Person B markiert war. In einem anderen Beispiel in der rechten Box verliert der Tracker die Spur von Person A (anfangs als ID_1 identifiziert) nach Frame 3 und identifiziert diese Person schließlich mit einer neuen ID (ID_2) in Frame n, was eine weitere Instanz eines ID-Switches zeigt.
State-of-the-Art
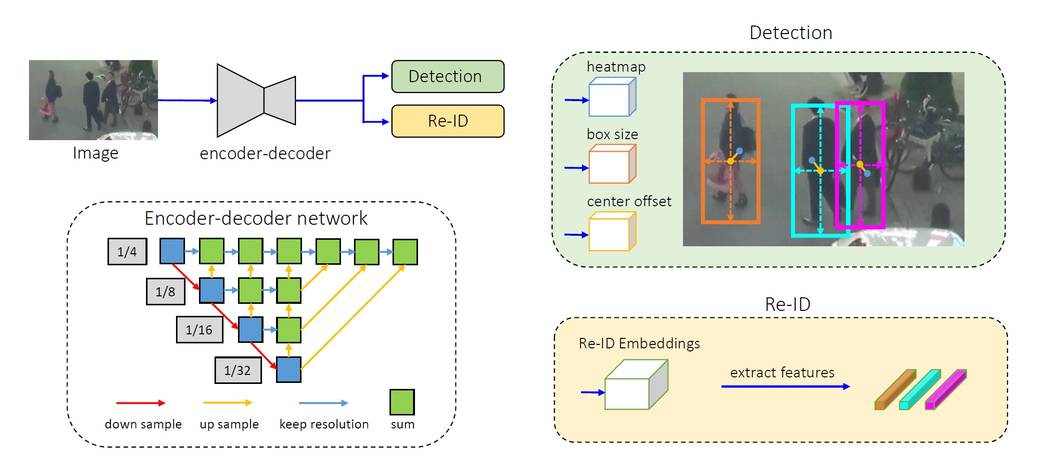
Wie ist die Architektur des FairMOT-Tracking-Algorithmus?
Er besteht aus einem einzigen Encoder-Decoder-Neuronalen Netz, das hochauflösende Feature-Maps des Bild-Frames extrahiert. Als One-Shot-Tracker speist er zwei parallele Köpfe für die Vorhersage von Bounding Boxes und Re-ID-Features, siehe Quelle.
Welche Objektdetektoren werden in Tracking-by-Detection-Trackern verwendet?
Die beliebtesten Objektdetektoren, die von SoTA-Tracking-Algorithmen verwendet werden, sind: Faster R-CNN, SSD und YOLOv3. Weitere Details finden Sie auf unserer FAQ-Seite zur Objekterkennung.
Welche Feature-Extraktionstechniken werden in Tracking-by-Detection-Trackern verwendet?
Während ältere Algorithmen lokale Merkmale wie optischen Fluss oder regionale Merkmale (z.B. Farbhistogramme, gradientenbasierte Merkmale oder Kovarianzmatrix) verwendeten, verwenden neuere Algorithmen auf Deep Learning basierende Merkmalsextraktionen. Die gängigsten Deep-Learning-Ansätze, die typischerweise auf Re-ID-Datensätzen trainiert werden, verwenden klassische CNNs zur Extraktion visueller Merkmale. Ein solcher Datensatz ist der MARS-Datensatz. Die folgende Abbildung zeigt ein Beispiel für ein CNN, das vom DeepSORT-Tracker für MOT verwendet wird: <p align="center"> 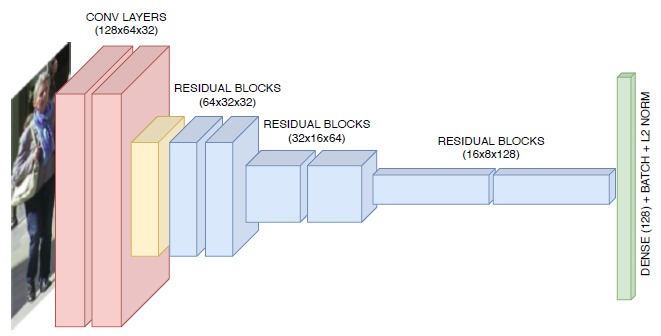 </p> Neuere Deep-Learning-Ansätze umfassen Siamese-CNN-Netzwerke, LSTM-Netzwerke oder CNNs mit Korrelationsfiltern. In Siamese-CNN-Netzwerken wird ein Paar identischer CNN-Netzwerke verwendet, um die Ähnlichkeit zwischen zwei Objekten zu messen, und die CNNs werden mit Verlustfunktionen trainiert, die Merkmale lernen, die sie am besten unterscheiden. <p align="center">
</p> Neuere Deep-Learning-Ansätze umfassen Siamese-CNN-Netzwerke, LSTM-Netzwerke oder CNNs mit Korrelationsfiltern. In Siamese-CNN-Netzwerken wird ein Paar identischer CNN-Netzwerke verwendet, um die Ähnlichkeit zwischen zwei Objekten zu messen, und die CNNs werden mit Verlustfunktionen trainiert, die Merkmale lernen, die sie am besten unterscheiden. <p align="center"> 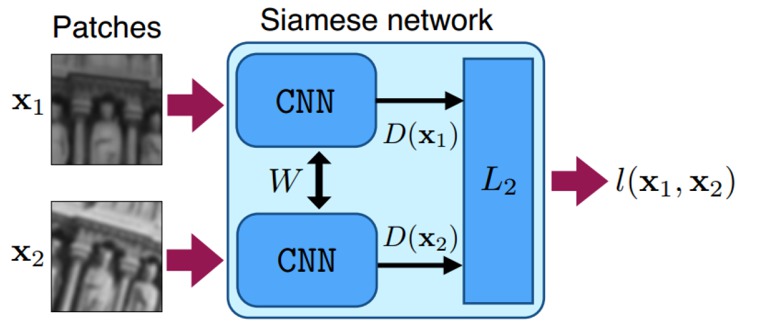 </p>
</p>
In einem LSTM-Netzwerk werden extrahierte Merkmale aus verschiedenen Detektionen in verschiedenen Zeit-Frames als Eingaben verwendet. Das Netzwerk prognostiziert die Bounding Box für den nächsten Frame basierend auf der Eingabe-Historie. <p align="center"> 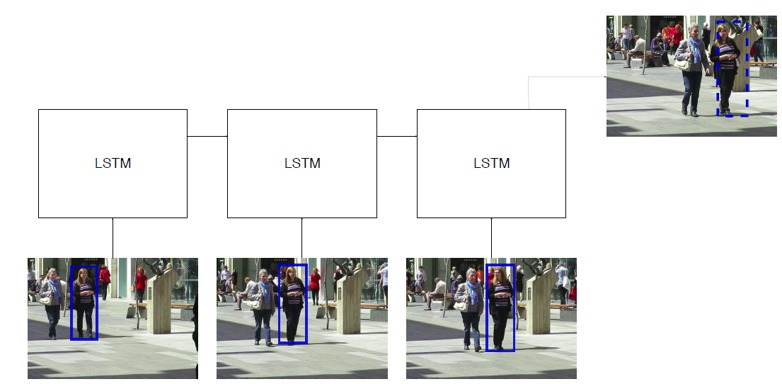 </p>
</p>
Korrelationsfilter können auch mit Feature-Maps aus CNN-Netzwerken gefaltet werden, um eine Vorhersage der Position des Ziels im nächsten Zeit-Frame zu erzeugen. Dies wurde von Ma et al wie folgt durchgeführt: <p align="center"> 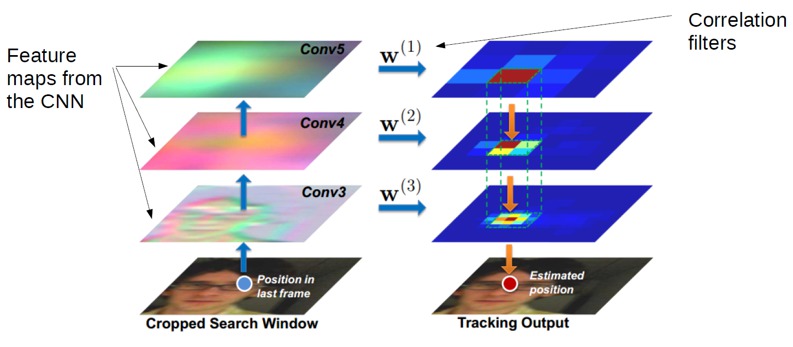 </p>
</p>
Welche Affinitäts- und Assoziationstechniken werden in Tracking-by-Detection-Trackern verwendet?
Einfache Ansätze verwenden Ähnlichkeits-/Affinitäts-Scores, die aus Distanzmaßen über die von CNN extrahierten Merkmale berechnet werden, um Objekt-Detektionen/Tracklets optimal mit etablierten Objekt-Spuren über aufeinanderfolgende Frames abzugleichen. Zur Durchführung dieses Abgleichs wird häufig der Hungarian (Huhn-Munkres) Algorithmus für die Online-Datenassoziation verwendet, während K-partit-Graph-Globaloptimierungstechniken für die Offline-Datenassoziation verwendet werden.
In komplexeren Deep-Learning-Ansätzen wird die Affinitätsberechnung oft mit der Merkmalsextraktion zusammengeführt. Beispielsweise geben Siamese CNNs und Siamese LSTMs direkt den Affinitäts-Score aus.
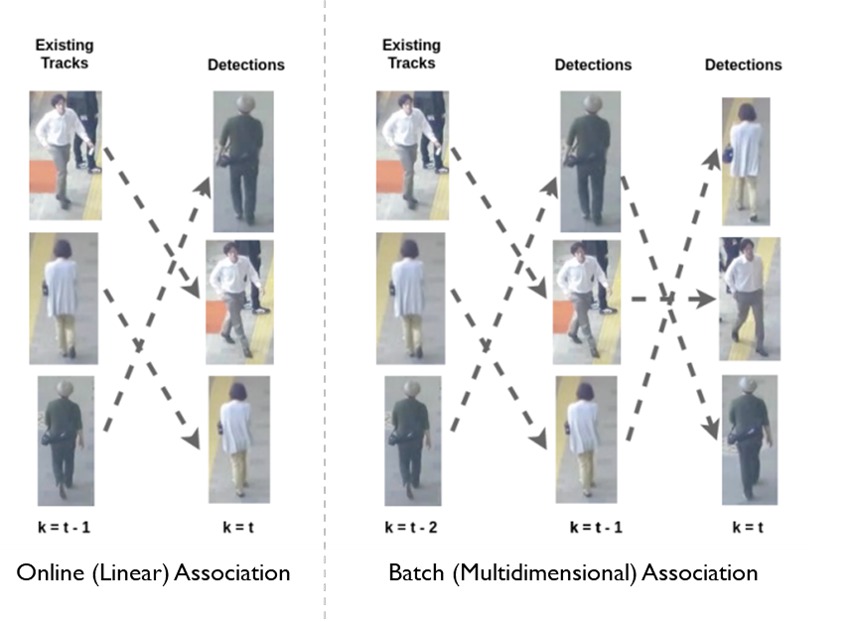
Was ist der Unterschied zwischen Online- und Offline-Tracking-Algorithmen?
Online- und Offline-Algorithmen unterscheiden sich in ihrem Schritt der Datenassoziation. Beim Online-Tracking werden die Detektionen in einem neuen Frame mit zuvor aus früheren Frames generierten Spuren assoziiert. So werden bestehende Spuren erweitert oder neue Spuren erstellt. Beim Offline-(Batch-)Tracking können alle Beobachtungen in einem Stapel von Frames global betrachtet werden (siehe Abbildung unten), d.h. sie werden durch Erzielung einer global optimalen Lösung zu Spuren verknüpft. Offline-Tracking kann bei Tracking-Problemen wie langfristiger Verdeckung oder räumlich nahen ähnlichen Zielen besser abschneiden. Offline-Tracking ist jedoch tendenziell langsamer und daher nicht für Aufgaben geeignet, die Echtzeitverarbeitung erfordern, wie z.B. autonomes Fahren.