Video-Annotation-Zusammenfassung für Aktionserkennung
Um einen Trainings- oder Evaluationsdatensatz für Aktionserkennung zu erstellen, müssen die Ground-Truth-Start-/Endpositionen von Aktionen in Videos annotiert werden. Wir haben verschiedene Tools dafür untersucht, und das Tool, das uns (bei weitem) am besten gefallen hat, heißt VGG Image Annotator (VIA), geschrieben von der VGG-Gruppe in Oxford.
Anleitung zur Verwendung des VIA-Tools
Wir geben nun einige Tipps/Schritte zur Verwendung des VIA-Tools. Eine voll funktionsfähige Live-Demo des Tools finden Sie hier.
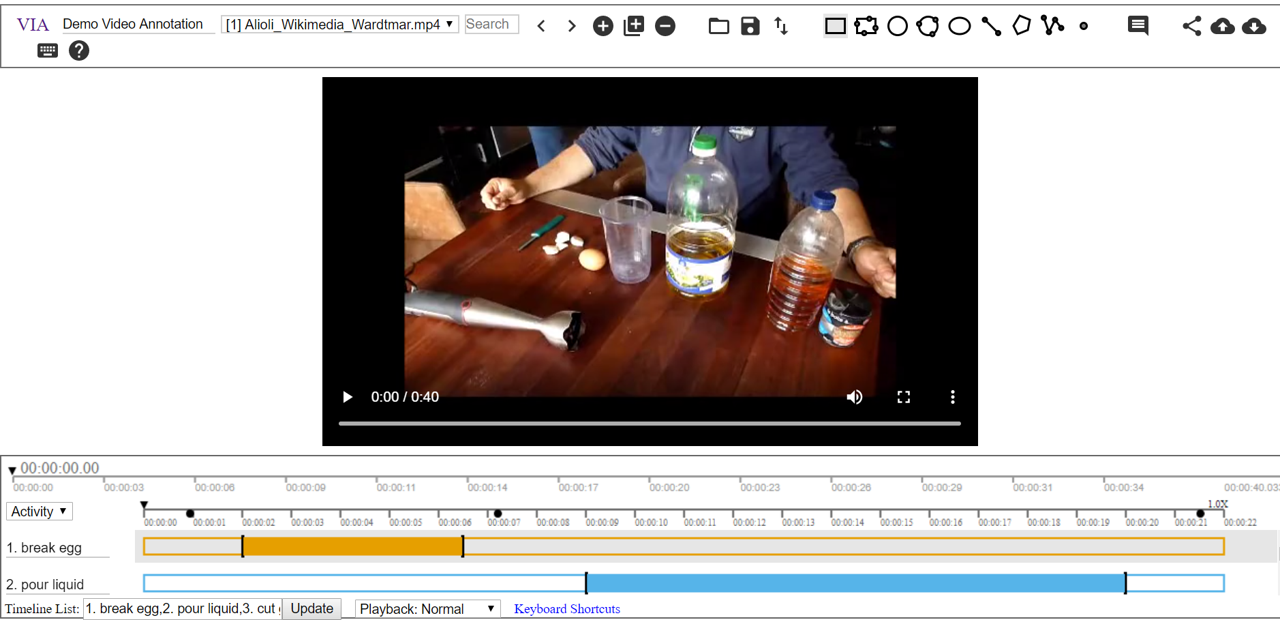
Screenshot des VIA-Tools
Verwendung des Tools für die Aktionserkennung
- Schritt 1: Laden Sie die Zip-Datei von diesem Link hier herunter.
- Schritt 2: Entpacken Sie das Tool und öffnen Sie die Datei via_video_annotator.html, um das Annotationstool zu öffnen. Hinweis: Die Unterstützung für einige Browser scheint nicht vollständig stabil zu sein – wir fanden Chrome am besten geeignet.
- Schritt 3: Importieren Sie die Videodatei(en) lokal mit
 oder über eine URL mit
oder über eine URL mit  .
. - Schritt 4: Verwenden Sie
 , um ein neues Attribut für die Aktionsannotation zu erstellen. Wählen Sie für Anchor Temporal Segment in Video or Audio. Um das erstellte Attribut zu sehen, klicken Sie erneut auf .
, um ein neues Attribut für die Aktionsannotation zu erstellen. Wählen Sie für Anchor Temporal Segment in Video or Audio. Um das erstellte Attribut zu sehen, klicken Sie erneut auf . - Schritt 5: Aktualisieren Sie die Timeline List mit den Aktionen, die Sie verfolgen möchten. Trennen Sie verschiedene Aktionen, z. B. „1. essen, 2. trinken“, um zwei separate Spuren für essen und trinken zu erhalten. Klicken Sie auf update, um die aktualisierten Spuren anzuzeigen.
- Schritt 6: Klicken Sie auf eine Spur, um Segmentannotationen für eine bestimmte Aktion hinzuzufügen. Verwenden Sie die Taste
a, um das temporale Segment zur aktuellen Zeit hinzuzufügen, undShift + a, um den Rand des temporären Segments auf die aktuelle Zeit zu aktualisieren. - Schritt 7: Exportieren Sie die Annotationen mit
 . Wählen Sie Only Temporal Segments as CSV, wenn Sie nur Annotationen für temporale Segmente haben.
. Wählen Sie Only Temporal Segments as CSV, wenn Sie nur Annotationen für temporale Segmente haben.
Skripte zur Verwendung mit dem VIA-Tool
Das VIA-Tool gibt Annotationen als CSV-Datei aus. Oft müssen wir jedoch jede annotierte Aktion als eigenen Clip und in separate Dateien schreiben. Diese Clips können dann als Trainingsbeispiele für Aktionserkennungsmodelle dienen. Wir stellen einige Skripte zur Verfügung, die beim Erstellen solcher Datensätze helfen.
- video_conversion.py - Konvertierung der Videoclips in ein Format, das das VIA-Tool lesen kann.
- clip_extraction.py - Extraktion jeder annotierten Aktion als separater Clip. Optional können „negative“ Clips generiert werden, in denen keine Aktion von Interesse vorkommt. Negative Clips können auf zwei Arten extrahiert werden: entweder alle fortlaufenden nicht überlappenden negativen Clips oder eine bestimmte Anzahl von negativen Beispielen wird zufällig ausgewählt. Dieses Verhalten kann über das Flag
contiguousgesteuert werden. Das Skript gibt Clips in Verzeichnisse aus, die für jede Klasse spezifisch sind, und generiert eine Label-Datei, die jeden Dateinamen dem Klassenlabel des Clips zuordnet. - split_examples.py - Teilt generierte Beispielclips in Trainings- und Evaluationssets auf. Optional können ein negativer Kandidatensatz und ein negativer Testdatensatz für das Hard-Negative-Mining generiert werden.
Vergleich von Annotationstools
Unten finden Sie eine Liste alternativer Benutzeroberflächen für die Annotation von Aktionen, aber unserer Meinung nach ist das VIA-Tool der mit Abstand beste Performer. Wir unterscheiden zwischen
- Annotation von Clips mit fester Länge: Dabei teilt die Benutzeroberfläche das Video in Clips mit fester Länge auf, und der Benutzer annotiert dann die Clips.
- Segmentationsannotation: Dabei annotiert der Benutzer direkt die genaue Start- und Endposition jeder Aktion. Dies ist zeitaufwändiger als die Annotation von Clips mit fester Länge, bietet aber eine höhere Lokalisierungsgenauigkeit.
Siehe auch die HACS Dataset Webpage für einige Beispiele, die diese beiden Arten von Annotationen zeigen.
| Toolname | Annotationstyp | Vorteile | Nachteile | Ob Open Source |
|---|---|---|---|---|
| MuViLab | Annotation von Clips mit fester Länge | <ul><li> Beschleunigt die Clip-Annotation durch gleichzeitige Anzeige vieler Clips</li> <li> Besonders hilfreich, wenn die Aktionen spärlich sind</li></ul> |
<ul><li> Nicht nützlich, wenn die Aktionen sehr kurz sind (z. B. eine Sekunde)</li></ul> | Open Source auf Github |
| VIA (VGG Image Annotator) | Segmentationsannotation | <ul><li> Leichtgewichtig, keine Voraussetzung außer dem Herunterladen einer Zip-Datei</li> <li> Aktives Entwicklungsprojekt auf Gitlab</li> <li> Unterstützung für: Annotation von Videos in hoher Präzision (auf Millisekunden und Frames), Vorschau der annotierten Clips, Export von Start- und Endzeiten der Aktionen nach CSV, Annotation mehrerer Aktionen in verschiedenen Spuren auf demselben Video</li> <li> Einfach zu erlernen und zu verwenden</li></ul> |
<ul><li> Code kann zu Instabilitäten führen, z. B. wird das Tool manchmal nicht reagieren.</li></ul> | Open Source auf Gitlab |
| ANVIL | Segmentationsannotation | <ul><li> Unterstützung für hochpräzise Annotationen, Export von Start- und Endzeiten.</li></ul> | <ul><li> Schwerwiegendere Voraussetzung mit erforderlichem Java</li> <li> Schwerer zu erlernen im Vergleich zu VIA mit vielen Spezifikationen usw.</li> <li> Java-bezogene Probleme können die Ausführung des Tools erschweren.</li></ul> |
Nicht Open Source, aber kostenlos zum Download |
| Action Annotation Tool | Segmentationsannotation | <ul><li> Fügen Sie Schlüsselbilder in Videos Beschriftungen hinzu</li> <li> Unterstützt hohe Präzision bis zu Millisekunden</li></ul> |
<ul><li> Viel weniger praktisch im Vergleich zu VIA oder ANVIL</li> <li> Nicht mehr aktiv entwickelt</li></ul> |
Open Source auf Github |
Referenzen
- Deep Learning for Videos: A 2018 Guide to Action Recognition.
- Zhao, H., et al. „Hacs: Human action clips and segments dataset for recognition and temporal localization.“ arXiv preprint arXiv:1712.09374 (2019).
- Kay, Will, et al. „The kinetics human action video dataset.“ arXiv preprint arXiv:1705.06950 (2017).
- Abhishek Dutta und Andrew Zisserman. 2019. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia (MM ’19), October 21–25, 2019, Nice, France. ACM, New York, NY, USA, 4 pages. https://doi.org/10.1145/3343031.3350535.