ai-agents-for-beginners
Kontext-Engineering für KI-Agenten

(Klicken Sie auf das obige Bild, um das Video dieser Lektion anzusehen)
Das Verständnis der Komplexität der Anwendung, für die Sie einen KI-Agenten entwickeln, ist wichtig, um einen zuverlässigen zu erstellen. Wir müssen KI-Agenten entwickeln, die Informationen effektiv verwalten, um komplexe Anforderungen zu erfüllen, die über das Prompt-Engineering hinausgehen.
In dieser Lektion werden wir uns ansehen, was Kontext-Engineering ist und welche Rolle es beim Aufbau von KI-Agenten spielt.
Einleitung
Diese Lektion behandelt
• Was Kontext-Engineering ist und warum es sich vom Prompt-Engineering unterscheidet.
• Strategien für effektives Kontext-Engineering, einschließlich der Art und Weise, wie Informationen geschrieben, ausgewählt, komprimiert und isoliert werden.
• Häufige Kontextfehler, die Ihren KI-Agenten zum Scheitern bringen können und wie Sie diese beheben.
Lernziele
Nach Abschluss dieser Lektion werden Sie wissen, wie Sie
• Kontext-Engineering definieren und es vom Prompt-Engineering unterscheiden können.
• Die Schlüsselkomponenten des Kontexts in Anwendungen für große Sprachmodelle (LLM) identifizieren können.
• Strategien zum Schreiben, Auswählen, Komprimieren und Isolieren von Kontext anwenden können, um die Leistung des Agenten zu verbessern.
• Häufige Kontextfehler wie Vergiftung, Ablenkung, Verwirrung und Konflikt erkennen und Minderungsstrategien implementieren können.
Was ist Kontext-Engineering?
Bei KI-Agenten ist der Kontext das, was die Planung eines KI-Agenten zur Ausführung bestimmter Aktionen antreibt. Kontext-Engineering ist die Praxis, sicherzustellen, dass der KI-Agent die richtigen Informationen hat, um den nächsten Schritt der Aufgabe abzuschließen. Das Kontextfenster ist in seiner Größe begrenzt, daher müssen wir als Agentenentwickler Systeme und Prozesse aufbauen, um das Hinzufügen, Entfernen und Kondensieren von Informationen im Kontextfenster zu verwalten.
Prompt-Engineering vs. Kontext-Engineering
Prompt-Engineering konzentriert sich auf einen einzigen Satz statischer Anweisungen, um die KI-Agenten effektiv mit einem Regelwerk zu leiten. Kontext-Engineering befasst sich mit der Verwaltung eines dynamischen Informationssatzes, einschließlich des anfänglichen Prompts, um sicherzustellen, dass der KI-Agent im Laufe der Zeit das erhält, was er benötigt. Die Hauptidee hinter dem Kontext-Engineering ist es, diesen Prozess wiederholbar und zuverlässig zu gestalten.
Arten von Kontext
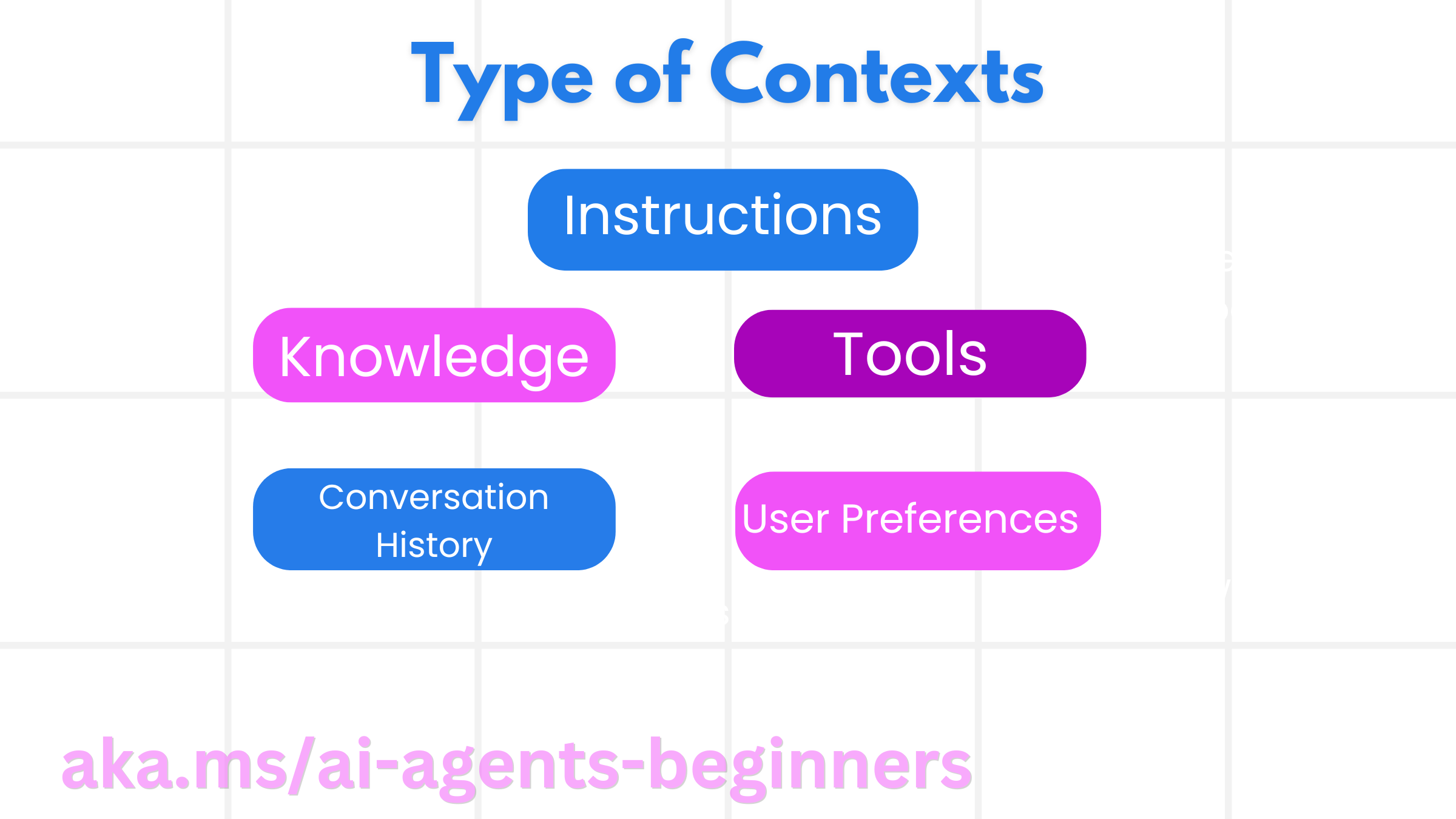
Es ist wichtig zu bedenken, dass Kontext nicht nur eine Sache ist. Die Informationen, die der KI-Agent benötigt, können aus einer Vielzahl verschiedener Quellen stammen, und es liegt an uns, sicherzustellen, dass der Agent Zugriff auf diese Quellen hat.
Die Arten von Kontext, die ein KI-Agent verwalten muss, umfassen
• Anweisungen: Dies sind wie die „Regeln“ des Agenten – Prompts, Systemnachrichten, Few-Shot-Beispiele (die dem KI zeigen, wie etwas zu tun ist) und Beschreibungen von Werkzeugen, die er verwenden kann. Hier überschneiden sich der Fokus des Prompt-Engineerings und des Kontext-Engineerings.
• Wissen: Dies umfasst Fakten, aus Datenbanken abgerufene Informationen oder Langzeitgedächtnisse, die der Agent angesammelt hat. Dies beinhaltet die Integration eines Retrieval Augmented Generation (RAG)-Systems, wenn ein Agent Zugriff auf verschiedene Wissensspeicher und Datenbanken benötigt.
• Werkzeuge: Dies sind die Definitionen externer Funktionen, APIs und MCP-Server, die der Agent aufrufen kann, zusammen mit dem Feedback (Ergebnissen), das er bei ihrer Verwendung erhält.
• Konversationsverlauf: Der fortlaufende Dialog mit einem Benutzer. Mit der Zeit werden diese Gespräche länger und komplexer, was bedeutet, dass sie Platz im Kontextfenster beanspruchen.
• Benutzerpräferenzen: Informationen über die Vorlieben oder Abneigungen eines Benutzers im Laufe der Zeit. Diese könnten gespeichert und bei wichtigen Entscheidungen herangezogen werden, um dem Benutzer zu helfen.
Strategien für effektives Kontext-Engineering
Planungsstrategien
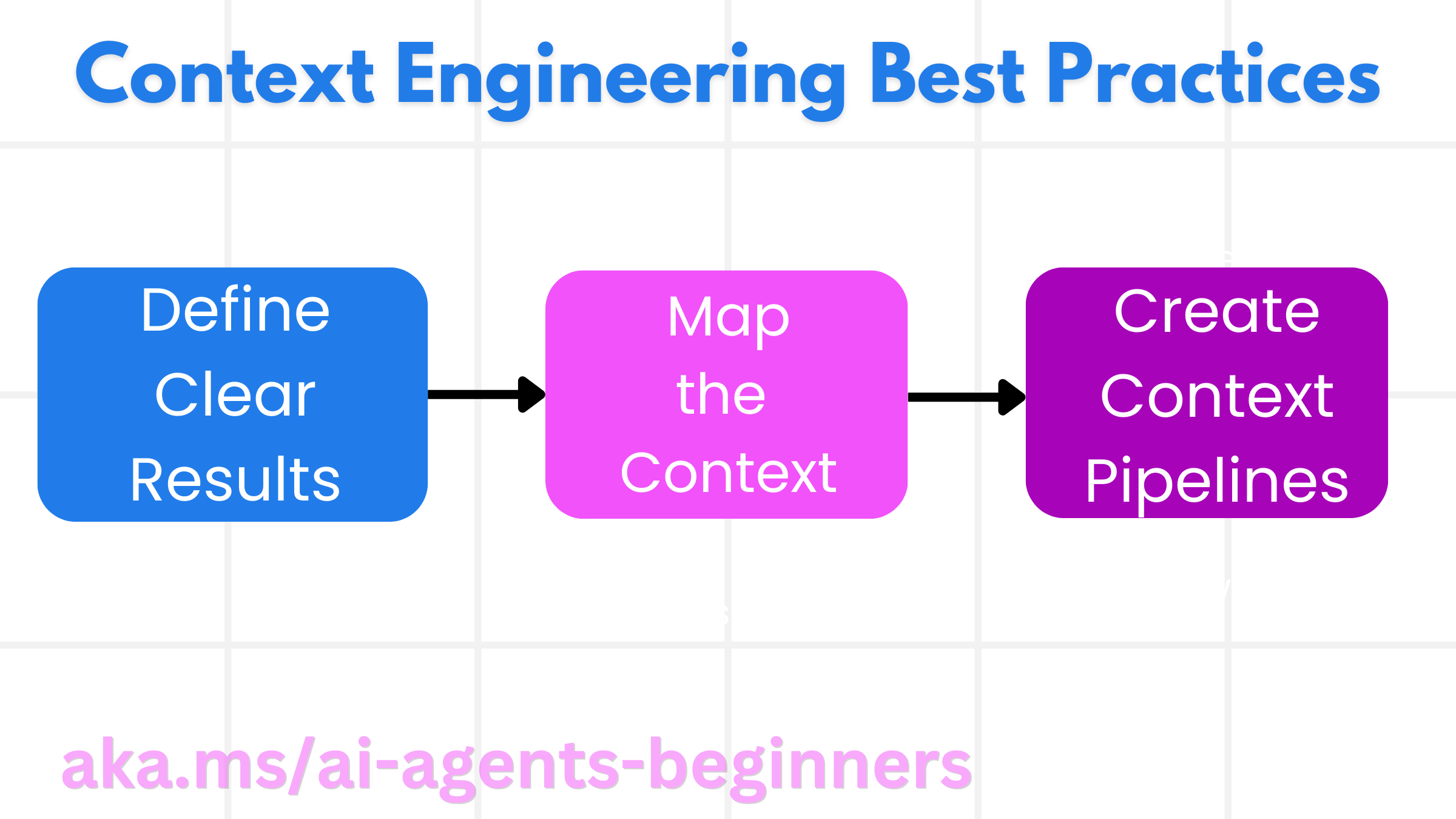
Gutes Kontext-Engineering beginnt mit guter Planung. Hier ist ein Ansatz, der Ihnen hilft, über die Anwendung des Konzepts des Kontext-Engineerings nachzudenken.
- Klare Ergebnisse definieren – Die Ergebnisse der Aufgaben, die KI-Agenten zugewiesen werden, sollten klar definiert sein. Beantworten Sie die Frage: „Wie wird die Welt aussehen, wenn der KI-Agent seine Aufgabe abgeschlossen hat?“ Mit anderen Worten, welche Veränderung, Information oder Antwort sollte der Benutzer nach der Interaktion mit dem KI-Agenten haben.
- Kontext zuordnen – Sobald Sie die Ergebnisse des KI-Agenten definiert haben, müssen Sie die Frage beantworten: „Welche Informationen benötigt der KI-Agent, um diese Aufgabe zu erfüllen?“ So können Sie mit der Zuordnung des Kontexts beginnen, woher diese Informationen stammen können.
- Kontext-Pipelines erstellen – Jetzt, da Sie wissen, wo sich die Informationen befinden, müssen Sie die Frage beantworten: „Wie erhält der Agent diese Informationen?“ Dies kann auf verschiedene Weise geschehen, einschließlich RAG, der Nutzung von MCP-Servern und anderen Tools.
Praktische Strategien
Planung ist wichtig, aber sobald die Informationen in das Kontextfenster unseres Agenten fließen, müssen wir praktische Strategien zu deren Verwaltung haben.
Kontextverwaltung
Während einige Informationen automatisch zum Kontextfenster hinzugefügt werden, geht es beim Kontext-Engineering darum, eine aktivere Rolle bei dieser Information zu spielen, was durch einige Strategien geschehen kann.
-
Agent Scratchpad Dies ermöglicht es einem KI-Agenten, sich während einer einzelnen Sitzung Notizen zu relevanten Informationen über die aktuellen Aufgaben und Benutzerinteraktionen zu machen. Dies sollte außerhalb des Kontextfensters in einer Datei oder einem Laufzeitobjekt existieren, auf das der Agent während dieser Sitzung bei Bedarf später zugreifen kann.
-
Gedächtnisse Scratchpads eignen sich gut für die Verwaltung von Informationen außerhalb des Kontextfensters einer einzelnen Sitzung. Gedächtnisse ermöglichen es Agenten, relevante Informationen über mehrere Sitzungen hinweg zu speichern und abzurufen. Dies kann Zusammenfassungen, Benutzerpräferenzen und Feedback für zukünftige Verbesserungen umfassen.
-
Kontext komprimieren Sobald das Kontextfenster wächst und sich seinem Limit nähert, können Techniken wie Zusammenfassung und Kürzung verwendet werden. Dies beinhaltet entweder das Beibehalten nur der relevantesten Informationen oder das Entfernen älterer Nachrichten.
-
Multi-Agenten-Systeme Die Entwicklung von Multi-Agenten-Systemen ist eine Form des Kontext-Engineerings, da jeder Agent sein eigenes Kontextfenster hat. Wie dieser Kontext geteilt und an verschiedene Agenten weitergegeben wird, ist etwas, das beim Aufbau dieser Systeme ebenfalls geplant werden muss.
-
Sandbox-Umgebungen Wenn ein Agent Code ausführen oder große Mengen an Informationen in einem Dokument verarbeiten muss, kann dies eine große Anzahl von Token zur Verarbeitung der Ergebnisse erfordern. Anstatt all dies im Kontextfenster zu speichern, kann der Agent eine Sandbox-Umgebung nutzen, die in der Lage ist, diesen Code auszuführen und nur die Ergebnisse und andere relevante Informationen zu lesen.
-
Runtime State Objects Dies geschieht durch die Erstellung von Informationscontainern zur Verwaltung von Situationen, in denen der Agent Zugriff auf bestimmte Informationen haben muss. Für eine komplexe Aufgabe würde dies einem Agenten ermöglichen, die Ergebnisse jeder Unteraufgabe Schritt für Schritt zu speichern, sodass der Kontext nur mit dieser spezifischen Unteraufgabe verbunden bleibt.
Beispiel für Kontext-Engineering
Nehmen wir an, wir möchten, dass ein KI-Agent „Buchen Sie mir eine Reise nach Paris.“
• Ein einfacher Agent, der nur Prompt-Engineering verwendet, könnte einfach antworten: „Okay, wann möchten Sie nach Paris reisen?“ Er hat nur Ihre direkte Frage zu dem Zeitpunkt verarbeitet, an dem der Benutzer sie gestellt hat.
• Ein Agent, der die abgedeckten Kontext-Engineering-Strategien anwendet, würde viel mehr tun. Noch bevor er antwortet, könnte sein System
◦ Ihren Kalender überprüfen auf verfügbare Termine (Abruf von Echtzeitdaten).
◦ Vergangene Reisepräferenzen abrufen (aus dem Langzeitgedächtnis) wie Ihre bevorzugte Fluggesellschaft, Ihr Budget oder ob Sie Direktflüge bevorzugen.
◦ Verfügbare Tools für Flug- und Hotelbuchungen identifizieren.
- Dann könnte eine Beispielantwort lauten: „Hallo [Ihr Name]! Ich sehe, Sie haben in der ersten Oktoberwoche frei. Soll ich nach Direktflügen nach Paris mit [Bevorzugte Fluggesellschaft] innerhalb Ihres üblichen Budgets von [Budget] suchen?“. Diese reichhaltigere, kontextbezogene Antwort demonstriert die Leistungsfähigkeit des Kontext-Engineerings.
Häufige Kontextfehler
Kontextvergiftung
Was es ist: Wenn eine Halluzination (falsche Information, die vom LLM generiert wurde) oder ein Fehler in den Kontext gelangt und wiederholt referenziert wird, was dazu führt, dass der Agent unmögliche Ziele verfolgt oder unsinnige Strategien entwickelt.
Was zu tun ist: Kontextvalidierung und Quarantäne implementieren. Validieren Sie Informationen, bevor sie in das Langzeitgedächtnis aufgenommen werden. Wenn eine potenzielle Vergiftung erkannt wird, starten Sie neue Kontextthreads, um die schlechte Information nicht zu verbreiten.
Beispiel für Reisebuchung: Ihr Agent halluziniert einen Direktflug von einem kleinen lokalen Flughafen zu einer entfernten internationalen Stadt, die tatsächlich keine internationalen Flüge anbietet. Dieses nicht existierende Flugdetail wird in den Kontext gespeichert. Später, wenn Sie den Agenten bitten zu buchen, versucht er immer wieder, Tickets für diese unmögliche Route zu finden, was zu wiederholten Fehlern führt.
Lösung: Implementieren Sie einen Schritt, der die Existenz und die Routen des Fluges anhand einer Echtzeit-API validiert, bevor das Flugdetail in den Arbeitskontext des Agenten aufgenommen wird. Wenn die Validierung fehlschlägt, wird die fehlerhafte Information „unter Quarantäne gestellt“ und nicht weiter verwendet.
Kontext-Ablenkung
Was es ist: Wenn der Kontext so groß wird, dass sich das Modell zu sehr auf die angesammelte Historie konzentriert, anstatt das während des Trainings Gelernte zu nutzen, was zu repetitiven oder unhilfreichen Aktionen führt. Modelle können Fehler machen, noch bevor das Kontextfenster voll ist.
Was zu tun ist: Kontextzusammenfassung verwenden. Komprimieren Sie angesammelte Informationen periodisch zu kürzeren Zusammenfassungen, wobei wichtige Details beibehalten und redundante Historie entfernt werden. Dies hilft, den Fokus „zurückzusetzen“.
Beispiel für Reisebuchung: Sie diskutieren schon lange über verschiedene Traumreiseziele, einschließlich einer detaillierten Beschreibung Ihrer Rucksackreise vor zwei Jahren. Wenn Sie schließlich bitten, „finden Sie mir einen günstigen Flug für nächsten Monat“, verheddert sich der Agent in den alten, irrelevanten Details und fragt immer wieder nach Ihrer Rucksackausrüstung oder früheren Reiserouten und vernachlässigt Ihre aktuelle Anfrage.
Lösung: Nach einer bestimmten Anzahl von Zügen oder wenn der Kontext zu groß wird, sollte der Agent die jüngsten und relevantesten Teile der Konversation zusammenfassen – sich auf Ihre aktuellen Reisedaten und Ihr Reiseziel konzentrieren – und diese komprimierte Zusammenfassung für den nächsten LLM-Aufruf verwenden und den weniger relevanten historischen Chat verwerfen.
Kontext-Verwirrung
Was es ist: Wenn unnötiger Kontext, oft in Form von zu vielen verfügbaren Werkzeugen, dazu führt, dass das Modell schlechte Antworten generiert oder irrelevante Werkzeuge aufruft. Kleinere Modelle sind davon besonders betroffen.
Was zu tun ist: Implementieren Sie Tool-Loadout-Management mit RAG-Techniken. Speichern Sie Tool-Beschreibungen in einer Vektordatenbank und wählen Sie nur die relevantesten Tools für jede spezifische Aufgabe aus. Forschungen zeigen, dass die Auswahl der Tools auf weniger als 30 begrenzt werden sollte.
Beispiel für Reisebuchung: Ihr Agent hat Zugriff auf Dutzende von Werkzeugen: book_flight, book_hotel, rent_car, find_tours, currency_converter, weather_forecast, restaurant_reservations usw. Sie fragen: „Was ist der beste Weg, um mich in Paris fortzubewegen?“ Aufgrund der schieren Anzahl von Werkzeugen wird der Agent verwirrt und versucht, book_flight innerhalb von Paris aufzurufen, oder rent_car, obwohl Sie öffentliche Verkehrsmittel bevorzugen, da sich die Tool-Beschreibungen überschneiden könnten oder er einfach nicht das beste Tool unterscheiden kann.
Lösung: Verwenden Sie RAG für Tool-Beschreibungen. Wenn Sie nach Fortbewegungsmöglichkeiten in Paris fragen, ruft das System dynamisch nur die relevantesten Tools wie rent_car oder public_transport_info basierend auf Ihrer Anfrage ab und präsentiert dem LLM ein fokussiertes „Loadout“ von Tools.
Kontext-Konflikt
Was es ist: Wenn widersprüchliche Informationen im Kontext vorhanden sind, was zu inkonsistentem Denken oder schlechten Endergebnissen führt. Dies geschieht oft, wenn Informationen schrittweise eintreffen und frühe, falsche Annahmen im Kontext verbleiben.
Was zu tun ist: Verwenden Sie Kontextbereinigung und Auslagerung. Bereinigung bedeutet, veraltete oder widersprüchliche Informationen zu entfernen, wenn neue Details eintreffen. Auslagerung gibt dem Modell einen separaten „Scratchpad“-Arbeitsbereich, um Informationen zu verarbeiten, ohne den Hauptkontext zu überladen.
Beispiel für Reisebuchung: Sie sagen Ihrem Agenten zunächst: „Ich möchte Economy Class fliegen.“ Später in der Konversation ändern Sie Ihre Meinung und sagen: „Für diese Reise fliegen wir stattdessen Business Class.“ Wenn beide Anweisungen im Kontext verbleiben, erhält der Agent möglicherweise widersprüchliche Suchergebnisse oder ist verwirrt, welche Präferenz priorisiert werden soll.
Lösung: Implementieren Sie Kontextbereinigung. Wenn eine neue Anweisung eine alte widerspricht, wird die ältere Anweisung aus dem Kontext entfernt oder explizit überschrieben. Alternativ kann der Agent einen Scratchpad verwenden, um widersprüchliche Präferenzen abzugleichen, bevor er eine Entscheidung trifft, und sicherstellen, dass nur die endgültige, konsistente Anweisung seine Handlungen leitet.
Haben Sie weitere Fragen zu Kontext-Engineering?
Treten Sie dem Azure AI Foundry Discord bei, um andere Lernende zu treffen, Sprechstunden zu besuchen und Ihre Fragen zu KI-Agenten beantwortet zu bekommen.